
 Netty中的HashedWheelTimer
Netty中的HashedWheelTimer
Netty作为一个非阻塞I/O客户端-服务器框架,自然要维护大量的连接,每一个连接都包含着许多定时任务. 例如发送超时,定时重试,心跳检测等,如果每个定时任务都启动一个Timer会消耗大量的资源. 所以,Netty提供了专门用于维护大量Timer调度的工具HashedWheelTimer.
该篇文章源码解析部分大量借鉴了netty源码解读之时间轮算法实现-HashedWheelTimer (opens new window), 但由于使用的Netty版本不同,有些细节稍有不同,该篇文章的源码解析基于Netty:4.1.32版本.
# 解决方案
这个解决方案是基于George Varghese 和 Tony Lauck 1996 年的论文: Hashed and Hierarchical Timing Wheels: data structures to efficiently implement a timer facility (opens new window) 进行的实现.
# HashedWheelTimer
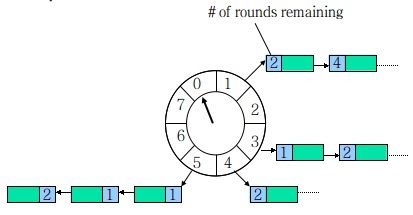
HashedWheelTimer是一个环形结构,可以联想为一个时钟,一个格子代表一段时间(每个格子越小,精度越高), 用一个List保存在该格子上的所有任务,同时一个指针随着时间的流逝一格一格转动,并执行对应List中所有到期的任务. 任务通过 取模 决定应该放入哪个格子.
以上图为例,假设一个格子是1秒,则整个wheel能表示的时间段为8s,假设当前指针指向2,此时需要调度一个3s后执行的任务, 显然应该加入到(2+3=5)的方格中,指针再走3次就可以执行了;如果任务要在10s后执行,应该等指针走完一个round零2格再执行, 因此应放入4,同时将round(1)保存到任务中。检查到期任务应当只执行round为0的,格子上其他任务的round应减1.
// 添加任务
* schedule: O(1)
// 删除/取消任务
* cancel: O(1)
// 过期/执行任务-->格子越多,每个格子对应的list就越短,越接近O(1).最坏情况下所有任务都在一个格子中
* expire: 最坏情况O(n),平均O(1)
其中比较重要的四个概念
tick: 时间轮里每一格
tickDuration: 每一格的时长
tickPerWheel: 时间轮总共有多少格
newTimeout: 定时任务分配到时间轮
# 实际使用
# 实例1:
/**
* tickDuration: 每 tick 一次的时间间隔, 每 tick 一次就会到达下一个槽位
* ticksPerWheel: 轮中的 slot 数
*/
@Test
public void testHashedWheelTimer2() throws InterruptedException {
// 1000ms一格,一轮16格(一般是2的N次幂,这样可以把hash转换为&0xFFFF)
HashedWheelTimer hashedWheelTimer = new HashedWheelTimer(1000,TimeUnit.MILLISECONDS, 4 );
System.out.println(LocalTime.now()+" submitted");
// 创建Timer
hashedWheelTimer.newTimeout((t) -> {
System.out.println(LocalTime.now() + " Task1");
}, 5, TimeUnit.SECONDS);
TimeUnit.SECONDS.sleep(500);
}
示例1的执行结果为:
LocalTime.now()为获取当前时间
13:46:07.603 submitted
13:46:13.613 Task1
# 示例2:
@Test
public void testHashedWheelTimer() throws InterruptedException {
// 1000ms一格,一轮16格(一般是2的N次幂,这样可以把hash转换为&0xFFFF)
HashedWheelTimer hashedWheelTimer = new HashedWheelTimer(1000, TimeUnit.MILLISECONDS, 4);
System.out.println(LocalTime.now() + " submitted");
hashedWheelTimer.newTimeout((t) -> {
System.out.println(LocalTime.now() + " TASK1");
// sleep 10S
TimeUnit.SECONDS.sleep(10);
}, 5, TimeUnit.SECONDS);
hashedWheelTimer.newTimeout((t) -> {
System.out.println(LocalTime.now() + " TASK2");
}, 8, TimeUnit.SECONDS);
TimeUnit.SECONDS.sleep(500);
}
示例2的执行结果:
13:50:37.606 submitted
13:50:43.615 TASK1
13:50:53.621 TASK2
由上面结果可以得出,当前一个任务执行时间过长的时候,会影响到后续的到期执行时间的. 也就是说其中的任务是串行执行的.所以要求任务的执行时间要短.(可以在定时任务中启动线程执行操作)
# 源码分析
# 构造方法
public HashedWheelTimer(
ThreadFactory threadFactory, // 用来创建worker线程
long tickDuration, // tick的时长,也就是指针多久转一格
TimeUnit unit, // tickDuration的时间单位
int ticksPerWheel, // 一圈有几格
boolean leakDetection, // 是否开启内存泄露检测
long maxPendingTimeouts // 最大挂起超时限制,如果此值为0或为负,则不会假定最大挂起超时限制
) {
// 一些参数校验
if (threadFactory == null) {
throw new NullPointerException("threadFactory");
}
if (unit == null) {
throw new NullPointerException("unit");
}
if (tickDuration <= 0) {
throw new IllegalArgumentException("tickDuration must be greater than 0: " + tickDuration);
}
if (ticksPerWheel <= 0) {
throw new IllegalArgumentException("ticksPerWheel must be greater than 0: " + ticksPerWheel);
}
// 创建时间轮基本的数据结构,一个数组.长度为不小于ticksPerWheel的最小2的n次方
wheel = createWheel(ticksPerWheel);
// 这是一个标示符,用来快速计算任务应该呆的格子。
// 我们知道,给定一个deadline的定时任务,其应该呆的格子=deadline%wheel.length.但是%操作是个相对耗时的操作,所以使用一种变通的位运算代替:
// 因为一圈的长度为2的n次方,mask = 2^n-1后低位将全部是1,然后deadline&mast == deadline%wheel.length
// java中的HashMap也是使用这种处理方法
mask = wheel.length - 1;
// 转换成纳秒处理
long duration = unit.toNanos(tickDuration);
// 校验是否存在溢出。即指针转动的时间间隔不能太长而导致tickDuration*wheel.length>Long.MAX_VALUE
if (duration >= Long.MAX_VALUE / wheel.length) {
throw new IllegalArgumentException(String.format(
"tickDuration: %d (expected: 0 < tickDuration in nanos < %d",
tickDuration, Long.MAX_VALUE / wheel.length));
}
// 校验tick的时长不能小于1ms,如果小于1ms就打印一个警告,然后将tickDuration设置为1ms
if (duration < MILLISECOND_NANOS) {
if (logger.isWarnEnabled()) {
logger.warn("Configured tickDuration %d smaller then %d, using 1ms.",
tickDuration, MILLISECOND_NANOS);
}
this.tickDuration = MILLISECOND_NANOS;
} else {
this.tickDuration = duration;
}
// 创建worker线程
workerThread = threadFactory.newThread(worker);
// 这里默认是启动内存泄露检测:当HashedWheelTimer实例超过当前cpu可用核数*4的时候,将发出警告
leak = leakDetection || !workerThread.isDaemon() ? leakDetector.open(this) : null;
// 设置最大挂起超时限制
this.maxPendingTimeouts = maxPendingTimeouts;
if (INSTANCE_COUNTER.incrementAndGet() > INSTANCE_COUNT_LIMIT &&
WARNED_TOO_MANY_INSTANCES.compareAndSet(false, true)) {
reportTooManyInstances();
}
}
# 启动,停止与添加任务
start() 启动时间轮的方法:
// 启动时间轮。这个方法其实不需要显示的主动调用,因为在添加定时任务(newTimeout()方法)的时候会自动调用此方法。
// 这个是合理的设计,因为如果时间轮里根本没有定时任务,启动时间轮也是空耗资源
public void start() {
// 判断当前时间轮的状态,如果是初始化,则启动worker线程,启动整个时间轮;如果已经启动则略过;如果是已经停止,则报错
// 这里是一个Lock Free的设计。因为可能有多个线程调用启动方法,这里使用AtomicIntegerFieldUpdater原子的更新时间轮的状态
switch (WORKER_STATE_UPDATER.get(this)) {
case WORKER_STATE_INIT:
if (WORKER_STATE_UPDATER.compareAndSet(this, WORKER_STATE_INIT, WORKER_STATE_STARTED)) {
workerThread.start();
}
break;
case WORKER_STATE_STARTED:
break;
case WORKER_STATE_SHUTDOWN:
throw new IllegalStateException("cannot be started once stopped");
default:
throw new Error("Invalid WorkerState");
}
// 等待worker线程初始化时间轮的启动时间
while (startTime == 0) {
try {
startTimeInitialized.await();
} catch (InterruptedException ignore) {
// Ignore - it will be ready very soon.
}
}
}
AtomicIntegerFieldUpdater是JUC里面的类,原理是利用反射进行原子操作。 有比AtomicInteger更好的性能和更低得内存占用。跟踪这个类的github提交记录, 可以看到更详细的原因 (opens new window).
stop()停止时间轮的方法:
public Set<Timeout> stop() {
// worker线程不能停止时间轮,也就是加入的定时任务,不能调用这个方法。
// 不然会有恶意的定时任务调用这个方法而造成大量定时任务失效
if (Thread.currentThread() == workerThread) {
throw new IllegalStateException(
HashedWheelTimer.class.getSimpleName() +
".stop() cannot be called from " +
TimerTask.class.getSimpleName());
}
// 尝试CAS替换当前状态为“停止:2”。如果失败,则当前时间轮的状态只能是“初始化:0”或者“停止:2”。直接将当前状态设置为“停止:2“
if (!WORKER_STATE_UPDATER.compareAndSet(this, WORKER_STATE_STARTED, WORKER_STATE_SHUTDOWN)) {
// workerState can be 0 or 2 at this moment - let it always be 2.
WORKER_STATE_UPDATER.set(this, WORKER_STATE_SHUTDOWN);
if (leak != null) {
leak.close();
}
return Collections.emptySet();
}
// 终端worker线程
boolean interrupted = false;
while (workerThread.isAlive()) {
workerThread.interrupt();
try {
workerThread.join(100);
} catch (InterruptedException ignored) {
interrupted = true;
}
}
// 从中断中恢复
if (interrupted) {
Thread.currentThread().interrupt();
}
if (leak != null) {
leak.close();
}
// 返回未处理的任务
return worker.unprocessedTimeouts();
}
newTimeout()添加定时任务:
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
// 参数校验
if (task == null) {
throw new NullPointerException("task");
}
if (unit == null) {
throw new NullPointerException("unit");
}
long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();
// 校验最大挂起超时限制,如果maxPendingTimeouts小于/等于0时,不开启检测
if (maxPendingTimeouts > 0 && pendingTimeoutsCount > maxPendingTimeouts) {
pendingTimeouts.decrementAndGet();
throw new RejectedExecutionException("Number of pending timeouts ("
+ pendingTimeoutsCount + ") is greater than or equal to maximum allowed pending "
+ "timeouts (" + maxPendingTimeouts + ")");
}
// 如果时间轮没有启动,则启动
start();
// Add the timeout to the timeout queue which will be processed on the next tick.
// During processing all the queued HashedWheelTimeouts will be added to the correct HashedWheelBucket.
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
// Guard against overflow.
if (delay > 0 && deadline < 0) {
deadline = Long.MAX_VALUE;
}
// 计算任务的deadline
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
// 这里定时任务不是直接加到对应的格子中,而是先加入到一个队列里,然后等到下一个tick的时候,会从队列里取出最多100000个任务加入到指定的格子中
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
timeouts.add(timeout);
return timeout;
}
这里使用的Queue不是普通java自带的Queue的实现,而是使用JCTool–一个高性能的的并发Queue实现包。