(0) 内存数据结构
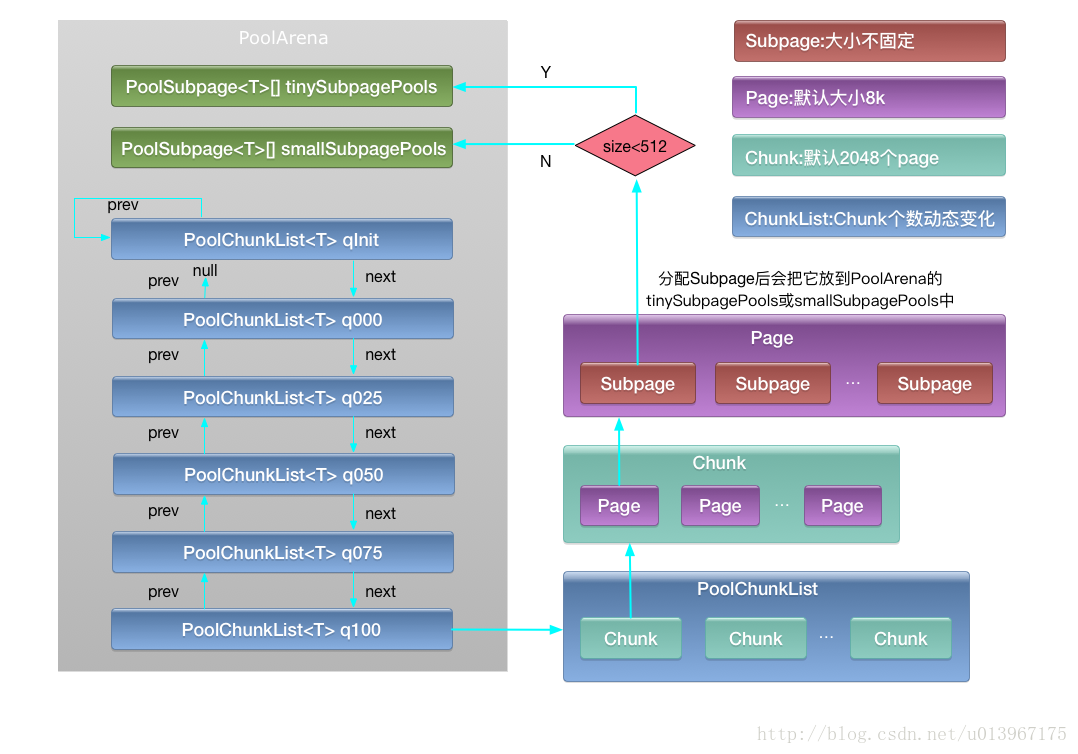
- 内存分级从上到下主要分为:Arena,ChunkList,Chunk,Page,SubPage五级;
-
PooledArena是一块连续的内存块,为了优化并发性能在Netty内存池中存在一个由多个Arena组成的数组,在多个线程进行内存分配时会按照轮询策略选择一个Arena进行内存分配;
-
一个PoolArena内存块是由两个SubPagePools(用来存储零碎内存)和多个ChunkList组成,两个SubpagePools数组分别为tinySubpagePools和smallSubpagePools。每个ChunkList里包含多个Chunk按照双向链表排列,每个Chunk里包含多个Page(默认2048个),每个Page(默认大小为8k字节)由多个Subpage组成。
-
每个ChunkList里包含的Chunk数量会动态变化,比如当该chunk的内存利用率变化时会向其它ChunkList里移动。
-
final PooledByteBufAllocator parent;
private final int maxOrder;
final int pageSize;
final int pageShifts;
final int chunkSize;
final int subpageOverflowMask;
final int numSmallSubpagePools;
final int directMemoryCacheAlignment;
final int directMemoryCacheAlignmentMask;
private final PoolSubpage<T>[] tinySubpagePools;
private final PoolSubpage<T>[] smallSubpagePools;
private final PoolChunkList<T> q050;
private final PoolChunkList<T> q025;
private final PoolChunkList<T> q000;
private final PoolChunkList<T> qInit;
private final PoolChunkList<T> q075;
private final PoolChunkList<T> q100;
-
内存池内存分配规则
-
对于小于PageSize大小的内存分配,会在tinySubPagePools和smallSubPagePools中分配,tinySubPagePools用来分配小于512字节的内存,smallSubPagePools用来分配大于512字节小于PageSize的内存;
-
对于大于PageSize小于ChunkSize的内存分配,会在PoolChunkList中的Chunk中分配
-
对于大于ChunkSize的内存分配,会之间直接创建非池化的Chunk来分配,并且该Chunk不会放在内存池中重用。
-
(1) 内存池的入口PoolByteBufAllocator
- 内存池进行内存分配是通过PooledByteBufAllocator类的buffer()方法实现的
public static void main(String[] args) {
ByteBuf buf = PooledByteBufAllocator.DEFAULT.buffer(1024); //默认直接内存
buf.writeBytes("hello".getBytes());
PooledByteBufAllocator p = new PooledByteBufAllocator(false); //堆内存(false)或者直接内存
ByteBuf buf1 = p.buffer(1024);
buf1.writeBytes("world".getBytes());
}
- 判断创建的缓冲区的类型,直接缓冲区或者堆缓冲区,如果在创建PooledByteBufAllocator实例时参数是false则为堆缓冲区
public ByteBuf buffer(int initialCapacity) {
if (directByDefault) {
return directBuffer(initialCapacity);
}
return heapBuffer(initialCapacity);
}
- 通过newHeapBuffer()方法创建堆缓冲区
public ByteBuf heapBuffer(int initialCapacity) {
return heapBuffer(initialCapacity, DEFAULT_MAX_CAPACITY);
}
@Override
public ByteBuf heapBuffer(int initialCapacity, int maxCapacity) {
if (initialCapacity == 0 && maxCapacity == 0) {
return emptyBuf;
}
validate(initialCapacity, maxCapacity);
return newHeapBuffer(initialCapacity, maxCapacity);
}
-
newHeapBuffer()方法首先从PoolThreadLocalCache中获取与线程绑定的缓存池PoolThreadCache,缓存池中保存着回收的内存;
- PoolThreadLocalCache继承了FastThreadLocal保存线程与内存缓冲池(PoolThreadCache)的映射,在进行内存分配时先映射中取出缓存内存块Arena,再将内存分配委托给内存块Arena的allocate()方法;
protected ByteBuf newHeapBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena<byte[]> heapArena = cache.heapArena;
final ByteBuf buf;
if (heapArena != null) {
buf = heapArena.allocate(cache, initialCapacity, maxCapacity);
} else {
buf = PlatformDependent.hasUnsafe() ?
new UnpooledUnsafeHeapByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledHeapByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}
- 如果不存在与线程对应的缓存则轮询分配一个Arean数组中的Arena内存块创建一个新的PoolThreadCache作为内存缓存
protected synchronized PoolThreadCache initialValue() {
final PoolArena<byte[]> heapArena = leastUsedArena(heapArenas);
final PoolArena<ByteBuffer> directArena = leastUsedArena(directArenas);
if (useCacheForAllThreads || Thread.currentThread() instanceof FastThreadLocalThread) {
return new PoolThreadCache(
heapArena, directArena, tinyCacheSize, smallCacheSize, normalCacheSize,
DEFAULT_MAX_CACHED_BUFFER_CAPACITY, DEFAULT_CACHE_TRIM_INTERVAL);
}
// No caching for non FastThreadLocalThreads.
return new PoolThreadCache(heapArena, directArena, 0, 0, 0, 0, 0);
}
(2) 内存块PoolArena
-
在应用层通过设置PooledByteBufAllocator来执行ByteBuf的分配,但是最终的内存分配工作被委托给PoolArena;由于Netty常用于高并发系统,所以各个线程进行内存分配时竞争不可避免,这可能会极大的影响内存分配的效率,为了缓解高并发时的线程竞争,Netty允许使用者创建多个分配器(Arena)来分离锁,提高内存分配效率,当然是以内存来作为代价的。
-
PoolByteBufAllocator将内存分配的任务委托给Arena进行,主要包括两步:一步是从Recycler对象池中获取复用的Buf对象,另外一步是为Buf对象分配内存;
PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) {
PooledByteBuf<T> buf = newByteBuf(maxCapacity); //获取复用对象
allocate(cache, buf, reqCapacity); //分配内存
return buf;
}
-
调用allocate()方法从Arena内存块中分配内存
-
判断需要分配的内存大小是否大于PageSize,如果小于PageSize则分配tiny内存或者small内存
- 如果需要分配的内存小于PageSize,判断是否小于512,如果小于则调用allocateTiny()方法进行tiny内存分配,否则调用allocateSmall()方法进行small内存分配;
-
如果需要分配的内存大于PageSize,再判断是否大于ChunkSize,如果小于ChunkSize则调用allocateNormal()方法进行normal内存分配;
-
如果需要分配的内存大于ChunkSize,内存池无法分配需要JVM分配则调用allocateHuge()方法在池外进行分配;
-
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
final int normCapacity = normalizeCapacity(reqCapacity);
if (isTinyOrSmall(normCapacity)) { // capacity < pageSize
int tableIdx;
PoolSubpage<T>[] table;
boolean tiny = isTiny(normCapacity);
if (tiny) { // < 512
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
tableIdx = tinyIdx(normCapacity);
table = tinySubpagePools;
} else {
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
final PoolSubpage<T> head = table[tableIdx];
/**
* Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and
* {@link PoolChunk#free(long)} may modify the doubly linked list as well.
*/
synchronized (head) {
final PoolSubpage<T> s = head.next;
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
long handle = s.allocate();
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
incTinySmallAllocation(tiny);
return;
}
}
synchronized (this) {
allocateNormal(buf, reqCapacity, normCapacity);
}
incTinySmallAllocation(tiny);
return;
}
if (normCapacity <= chunkSize) {
if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {
// was able to allocate out of the cache so move on
return;
}
synchronized (this) {
allocateNormal(buf, reqCapacity, normCapacity);
++allocationsNormal;
}
} else {
// Huge allocations are never served via the cache so just call allocateHuge
allocateHuge(buf, reqCapacity);
}
}
-
内存池的初始阶段,线程是没有内存缓存的,所以最开始的内存分配都需要在Chunk分配区进行分配;也就是说无论是tinySubpagePools还是smallSubpagePools成员,在内存池初始化时是不会预置内存的,所以最开始的内存分配都会进入PoolArena的allocateNormal方法:
- 调用allocateNormal()方法从Chunk级别上分配内存,从PoolChunkList中查找可用PoolChunk并进行内存分配,如果没有可用的PoolChunk则创建一个并加入到PoolChunkList中,完成此次内存分配
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
return;
}
// Add a new chunk.
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
long handle = c.allocate(normCapacity);
assert handle > 0;
c.initBuf(buf, handle, reqCapacity);
qInit.add(c);
}
- 从Arena中创建新的PoolChunk后根据其内存占用率放入相应的ChunkList中;
void add(PoolChunk<T> chunk) {
if (chunk.usage() >= maxUsage) {
nextList.add(chunk);
return;
}
chunk.parent = this;
if (head == null) {
head = chunk;
chunk.prev = null;
chunk.next = null;
} else {
chunk.prev = null;
chunk.next = head;
head.prev = chunk;
head = chunk;
}
}
(3) 内存块分配基本单元PoolChunk
-
PoolChunk的几个重要参数
-
memory,物理内存,内存请求者千辛万苦拐弯抹角就是为了得到它,在HeapArena中它就是一个chunkSize大小的byte数组;默认PoolChunk是由11层二叉树构成,也就是大小为ChunkSize=2048*PageSize;
-
memoryMap数组,内存分配控制信息,数组元素是一个32位的整数
-
subpages数组,页分配信息,数组元素的个数等于chunk中page的数量。
-
-
从Arena中创建PoolChunk后,通过调用PoolChunk.allocate()方法真正进行内存分配
- 在Chunk中的内存分配是根据需要分配的内存大小将Page内存页划分为SunPage,并将多余的SubPage加入到SubPagePools缓存中,将被分配的Page和SubPage在控制数组中进行标记;
private long allocateSubpage(int normCapacity) {
PoolSubpage<T> head = arena.findSubpagePoolHead(normCapacity);
synchronized (head) {
int d = maxOrder; // subpages are only be allocated from pages i.e., leaves
int id = allocateNode(d);
if (id < 0) {
return id;
}
final PoolSubpage<T>[] subpages = this.subpages;
final int pageSize = this.pageSize;
freeBytes -= pageSize;
int subpageIdx = subpageIdx(id);
PoolSubpage<T> subpage = subpages[subpageIdx];
if (subpage == null) {
subpage = new PoolSubpage<T>(head, this, id, runOffset(id), pageSize, normCapacity);
subpages[subpageIdx] = subpage;
} else {
subpage.init(head, normCapacity);
}
return subpage.allocate();
}
}
总结
-
内存池主要是将内存分配管理起来不经过JVM的内存分配,有效减小内存碎片避免内存浪费,同时也能减少频繁GC带来的性能影响;
-
内存池内存分配入口是PoolByteBufAllocator类,该类最终将内存分配委托给PoolArena进行;为了减少高并发下多线程内存分配碰撞带来的性能影响,PoolByteBufAllocator维护着一个PoolArena数组,线程通过轮询获取其中一个进行内存分配,进而实现锁分离;
-
内存分配的基本单元是PoolChunk,从PoolArena中分配获取一个PoolChunk,一个PoolChunk包含多个Page内存页,通过完全二叉树维护多个内存页用于内存分配;