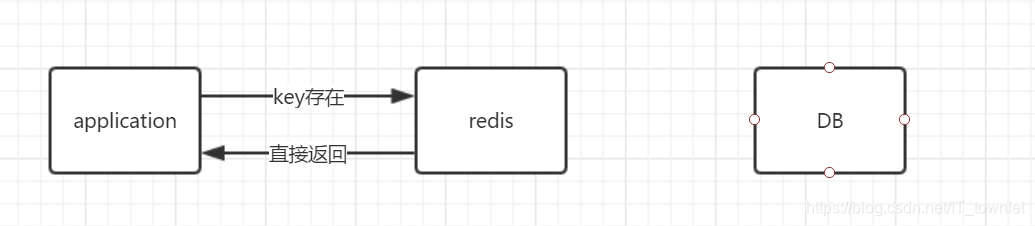
缓存访问的过程如下:
(1)应用访问缓存,假如数据存在,则直接返回数据
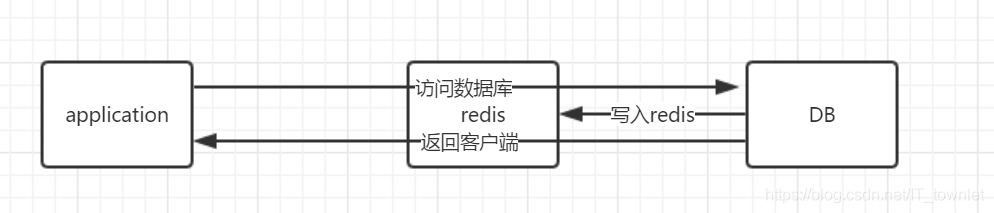
(2)数据在redis不存在,则去访问数据库,数据库查询到了直接返回应用,同时把结果写回redis
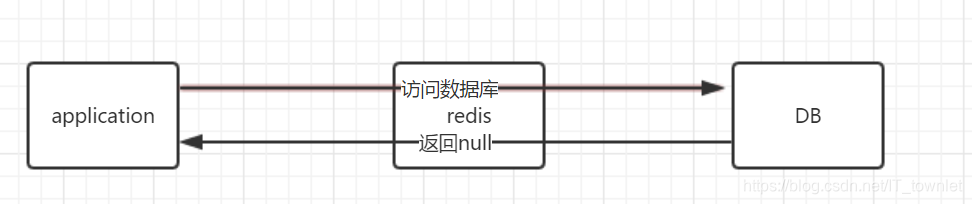
(3)数据在redis不存在,数据库也不存在,返回空,一般来说空值是不会写入redis的,如果反复请求同一条数据,那么则会发生缓存穿透。
当然解决方案是可以为这个key设置一个空值,同时写入redis,下次请求的时候就不会访问数据库,但是如果每次请求的是不同的key,同时这个key在数据库中也是不存在的,那这样依然会发生缓存穿透。
布隆过滤器
我们可以这样考虑,可以先判断key值是否存在,如果不存在,则不访问redis,那这样就可以拦截大量的请求,布隆过滤器恰好可以实现这样的需求。
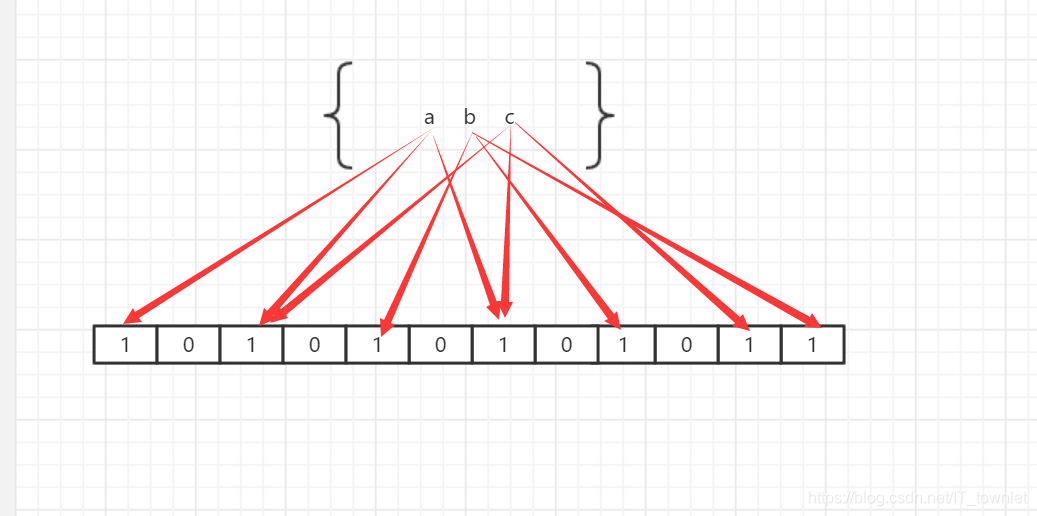
布隆过滤器本质是一个二进制向量,初始化的时候每一个位置都是0,如下图,比如说a经过hash算法后得到一个下标位置,接下来就会把下标的值改为1,图中所示的是没一个元素经过三次hash运算,每一个红线代表一次hash算法,为什么要运算三次呢,这是为了减少hash冲突,当然hash算法不一定是三次,经过多次不同维度的哈市算法后,就把a值映射到了二进制向量里面,这样的好处很多,可以节省空间,假如说a值是一串很长的字符串,那么经过映射后就可以只占三位长度,并且查找速度很快。
如果布隆过滤器判断元素存在,则不一定存在,如果不存在,则一定不存在
如何理解这句话,因为有可能你一个元素运算得到的下标恰好是别的元素的下标,如果经过运算后布隆过滤器判断不存在,也就是说至少有一个下标是为0的,那肯定是不存在的
布隆过滤器的使用
用Google的guava包已经有了布隆过滤器算法的实现,注意的是布隆过滤器有一定的误判率,不可能达到100%的精准,首先初始化项目的时候从数据库查询出来所有的key值,然后放到布隆过滤器中,guava包都实现了相应的put方法和hash算法。
加了布隆过滤器的过程如下
1,当应用访问的时候,先去布隆过滤器中判断kedy值,如果发觉没有key值不存在,直接返回
2、如果key值在布隆过滤器存在,则去访问redis,由于是有误判率的,所以redis也有可能不存在
3、那么这时候就去访问数据库,数据库不存在,那就直接返回空就行

如果误判率为3%,当有100万个请求同时过来的时候,布隆过滤器已经挡住了97万个请求,剩下3万个请求假如是误判的,这时候再访问数据库可以通过加锁的方式实现,只有竞争到锁了就去访问数据库,这样就完全可以解决缓存穿透问题
布隆过滤器的应用
比如说输入用户名的时候,可以马上检测出该用户名是否存在,黑名单机制,单词错误检测等