在之前的一个系列的文章里,我们从基本原理开始,一步步实现了基于 Vector Trie 的持久化 List 数据结构。 接下来将要研究的是使用 HAMT 这一数据结构实现持久化 Hash Table。
持久化数据结构简介 这篇文章里, 我们对比各种可以用来实现持久化数据结构的方案,详细介绍了 Vector Trie 这种数据结构,说明了用它实现 List 优势。 HAMT 的全称是 Hash Array Mapped Trie,它和 Vector Trie 一样,都利用了前缀树(Trie)这种数据结构作为底层数据结构, 但是由于 Map 本身和 List 之间性质的差别,HAMT 在很多方面进行了特别的处理。接下来我们先从原始 Hash Table 数据结构谈起, 逐步引出 HAMT 的设计原理。
Hash Table
Hash Table 是利用对象的 Hash 值对所储存的键进行散列从而实现快速的插入、删除和访问的数据结构。 在 Go 语言中的 map、Java 中的 HashTable 和 HashMap 和 Python 当中的 dict 都是 HashTable 的一种。 其基本原理是通过某一 Hash 函数将对象映射在某一虚拟空间上的一个点,并以此为依据将对象保存在内存上的固定位置上。 这样当需要访问这一对象时,依然使用同一 Hash 函数先计算出对象可能存在的位置,并尝试取出。
关于 Hash 和 Hash Table 的概念不再赘述,在这里我们主要需要着眼的是设计实现 Hash Table 所需要处理的几个关键问题:
- Hash 碰撞问题: 由于 Hash 函数是通过将对象映射到某一数值的方式获得对对象的一个快速的描摹, 因此尽管我们可以断言 Hash 值不同的的对象一定不同,但是并不能保证具有相同 Hash 值的对象一定相同。 因此,在实际应用中遇到 Hash 碰撞的问题,就需要进行处理。
- 时间效率问题: 对于所有数据结构来说,时间效率都是非常重要的考量因素。Hash Table 从理论上来说的均摊时间复杂度很好, 但是仍然需要考虑在某些极端条件下面的执行性能,以保证在各种情况下算法的时间效率不会退化。
- 空间效率问题: 一般来说,我们不能将 Hash 函数值域整个在内存中一次分配出来。一来这样做在存入元素很少的情况下非常浪费, 二来我们构造的 Hash 函数值域范围很大,一般无法直接分配。因此需要一种方法将空间使用压缩到合理的范围, 同时保持一定的空间效率。
- 并发同步问题: 和 List 一样,在现代多核盛行的计算环境内,Hash Table 实现的并发安全性也是一个重要的考虑因素。 Hash Table 的插入、访问和删除操作往往包含好连续的几步,如果不能保证这些步骤在一起原子的完成就可能会产生无法预计的结果。
以上四点在实现 Hash Table 的过程当中是互相联系的。比如说 Hash 碰撞问题就与时间效率和空间效率两个方面紧密相连。 一般来说,Hash 碰撞越多,Hash Table 的时间效率越差。根据碰撞处理策略的不同,还有可能影响空间效率。 反过来,如果空间分配的比较多,尽管空间效率下降,但是往往可以缓解 Hash 碰撞的概率,因此改善时间效率。 并发同步问题也与上述问题紧密相连,譬如说有的 Hash Table 实现在空间不足时需要重新分配空间, 这一操作既耗时,又包含很多的指令,对于并发安全提出了很高的要求。
HAMT 在以上四个方面都给出了自己的极佳的解决方案,很多学者将其称为理想(Ideal)的 Hash Table 实现。 在接下来介绍 HAMT 的原理之前,我们先给出在本文中对 Hash 函数的一些假定:
- Hash 函数的值是
int32类型 - Hash 函数的值域
int32类型的范围 - 对于两个不同的对象,总可以找到一个 Hash 函数使二者 Hash 值不同
HAMT 原理简介
之前介绍了 Vector Trie 实现的持久化 List,如果将这种 List 作为基础,直接套用传统 Hash Table 的实现方法, 其实就可以实现持久化的 HashMap 了。但是这种解决方案在时间效率、空间效率上都比较差。Hash Table 和 List 的一个区别在于 Hash Table 当中保存的元素是散列和稀疏的,不像 List 那样从下标 0 一直排列到 n。
然而只要把 List 当中下标必须连续的限制条件去掉,Vector Trie 本身就变成了一种相对传统 Array 更好的容器。 下图表示的 Vector Trie 说明了这一点:
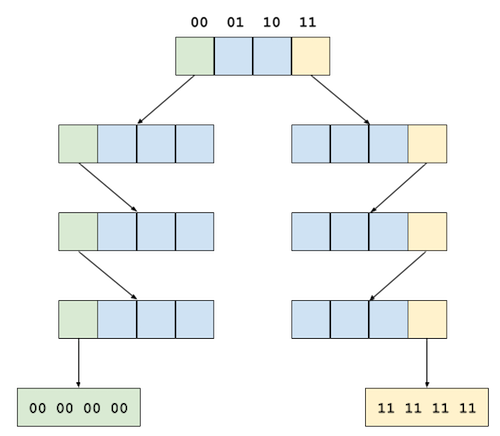 Variant of Vector Trie
Variant of Vector Trie
由上图可见,在 Vector Trie 表示的 Hash Table 中,每个元素的 Hash 值的范围是 0 (00 00 00 00) 到 255 (11 11 11 11)。 此时 Hash Table 当中只有两个元素,其中一个 hash 值是 0,另一个为 255。在传统 Array 实现的 Hash Table 当中我们需要分配一个长度 256 的数组来保存。而使用 Trie 只需要 7 个节点,共计 28 个单位的空间。 其它位置因为没有元素存在,那些节点可以直接节省掉。
这说明应用 Trie 树可以在节约空间效率方面具有很好的表现。事实上依靠 Trie 树我们可以直接把 0 到 232−1232−12^{32} - 1 (既int32) 范围的空间表示出来而不用直接分配全部内存——只有存在元素的分支会被按需地分配出来。事实上,Trie 树是线性空间上稀疏数组的一种很好的表示形式。
在引入 Trie 树作为数组的稀疏表示之后,我们已经大幅地提高空间效率并得到了不错的时间效率。尽管查询 Trie 树比直接访问数组更慢一些,但是由于我们表示的 Hash 空间足够宽广,在实际应用中遇见碰撞的概率极低, 因此在时间效率上还是很有竞争力的。
至此,在 Vector Trie 的基础上我们得到了通往 HAMT 的第一步:将元素的 Hash 值按位分割成固定宽度的序列,在 Trie 树上以这些序列按顺序查找元素应该存放的位置。然而 HAMT 并不止步于此,从图中容易看出, 我们还有两种优化方案可以达到更好的空间时间效率:
- 节约单个节点当中空间的浪费: 许多 Trie 节点中仍然有非常多的空位,设法将这些空位清除可以节省很多空间。
- 削减 Trie 树的高度: 保存在树中的两个元素的 Hash 值从第一位开始就不相同,理论上只需要检查最前面的几位就可以区分。 只使用 Hash 值中较高的比特位既可以节约空间,又可以提高时间效率。
在这两个方向,HAMT 都提出了不错的优化方案。
节点内部空间的压缩
如果我们依然使用固定 32 个元素宽度的 Trie 树节点,那么必然可能出现由于存入的元素比较稀疏而存在大量空位的现象, 为此我们要对节点内部空间进行压缩。压缩的方法是:
- 为每一个节点添加一个
int32类型的 Bit Map 字段,当这个字段某一比特位值为1代表在当前节点上对应的自节点出现了, 否则则代表没有出现 - 我们保存子元素时不再保留空间的空闲位置,而是将所有的子元素一个挨一个的紧密放置, 在存取时利用上一步添加的字段计算出所需的是哪一个子节点。
为了更清楚地解释上述做法,下面的示意图来描绘了进行节点内部压缩前后的节点内部结构:
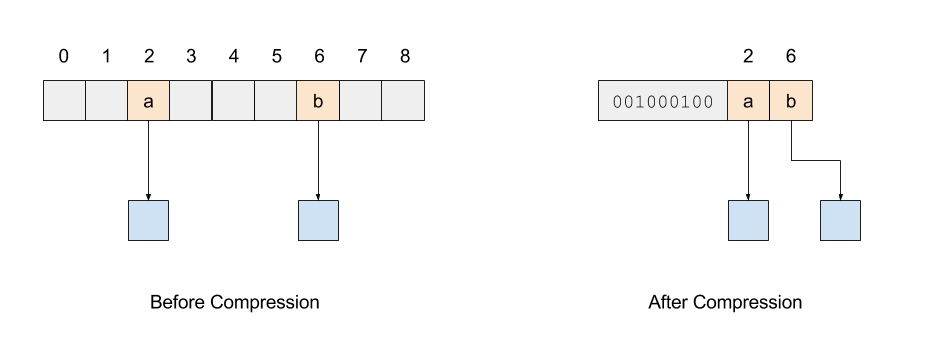 Trie Node Compression
Trie Node Compression
由上图可以看到,虽然压缩后的节点多增加了一个用于保存 Bit Map 的字段,但是由于省略了6个空置空间, 所以整体的内存消耗大大降低了。
要在压缩过的节点当中完成跟原来一样的查询逻辑,我们要建立压缩前后节点之间的对应关系。 在未压缩的节点中,由于每个自节点就在它序号所指定的内存位置,所以我们可以直接用下标访问它, 在压缩过的节点中这一性质不再有效,我们需要使用新增的 Bit Map 字段将节点的内存位置计算出来。
由上图可以看到,压缩前后子元素的相对顺序并没有改变,仍然是按照从小到大的顺序排列起来的, 这一点非常重要。根据这个性质,我们可以给出如下的算法:
- 如果指定序号在 Bit Map 字段中对应的比特位为
0,表明并不存在给定序号的子元素,因此可以立刻返回空值 - 如果指定序号在 Bit Map 字段中对应比特位为
1,则元素存在且它在压缩后节点中的位置下标等于在其之前出现的子元素的数量
第二条其实很好理解,因为压缩后元素的相对顺序不变,只是将空余空间剔除,因此如果从零开始编号, 设在所查询子元素之前出现的元素数量为n,那么所查询子元素就是第n+1个元素。因此其下标恰好是n。 利用 Bit Map 和位运算我们可以快速的计算出n的值。
譬如说,我们要查询在原节点中下标为i的元素,首先我们看一下 Bit Map 第 i 位的值是否为 1。 方法是使用位运算 (B >> i) & 1,其中 B 是 Bit Map 字段的值。如果检查结果为 1,说明元素存在,我们进一步计算它的位置。
显然,当前元素之前的元素数量n,就等于 Bit Map 当中从 0 到 i - 1 (包含两端)位比特位当中 1 的数量, 我们首先用 B & ((1 << i) - 1) 将那些位单独取出来并将其他位置设为0。其中,(i << i) - 1 得到的是 0 到 i - 1 位全为 1,其他位全为 0 的一个整型值。
得到这个结果之后,我们还需要把其中的 1 的数量计算出来。这一操作在计算机科学当中被称为 Pop Count, 进行这样的计算所得到的值又称为Hamming Weight。 Pop Count 是一种非常常用的操作,因此存在很多相关研究,有的 CPU 指令集(如 x86)还添加了专门的指令用于执行这一操作。
除了直接使用指令集或者简单地逐个计数,Hamming Weight 的快速计算有很多方法,下面的代码给出了在 int32 类型上快速计算 Pop Count 的一种实现方法。
const uint32_t m1 = 0x55555555; //binary: 0101...
const uint32_t m2 = 0x33333333; //binary: 00110011..
const uint32_t m4 = 0x0f0f0f0f; //binary: 4 zeros, 4 ones ...
const uint32_t m8 = 0x00ff00ff; //binary: 8 zeros, 8 ones ...
const uint32_t m16 = 0x0000ffff; //binary: 16 zeros, 16 ones ...
//This uses fewer arithmetic operations than any other known
//implementation on machines with slow multiplication.
int popcount32(uint32_t x)
{
x -= (x >> 1) & m1; //put count of each 2 bits into those 2 bits
x = (x & m2) + ((x >> 2) & m2); //put count of each 4 bits into those 4 bits
x = (x + (x >> 4)) & m4; //put count of each 8 bits into those 8 bits
x += x >> 8; //put count of each 16 bits into their lowest 8 bits
x += x >> 16; //put count of each 32 bits into their lowest 8 bits
return x & 0x7f;
}
关于 Pop Count 的计算本文不再赘述,相关内容可以参考 Wikipedia 上详细的介绍和计算方法的对比。由于在 HAMT 当中 Pop Count 是一个非常常用的操作,因此他的性能对最终实现的 Hash Table 的性能有显著的影响,在实现 HAMT 时,一定要根据目标平台的特点,选择合适的实现方法,可能的话应该直接使用 CPU 指令集支持的指令进行计算。
在获得到子元素在压缩后节点的内存下标之后,我们就可以像原来一样对节点进行查询访问了。
压缩 Trie 高度
在节点内部空间之外另一个可以节省空间的地方是 Trie 树的高度。 前面在利用这个 int32 宽的 Hash 值构造 Trie 树将我们的对象放置在内存中索引起来, 那么一个容易想到的优化就是在不产生混淆的情况下,我们没有必要一定使用 Hash 值的每一个二进制位。 也就是说,如果 Hash 值的较高的一部分二进制位已经可以在我们的 Hash Table 中唯一地标记这个对象了, 我们就不再利用后面的比特位。
下图展示了对 Trie 树高度的压缩。在左边的原始 Trie 树中存放了 Hash 值为 0(00 00 00 00) 和 127(01 11 11 11)的两个对象,中间是压缩高度的 Trie 树, 我们看到,由于当前 Hash Table 中只有两个元素,而这两个元素的 Hash 值从最开始就是不一样的, 所以在压缩之后,从高位开始第二位之后的 Hash 值不再被使用。
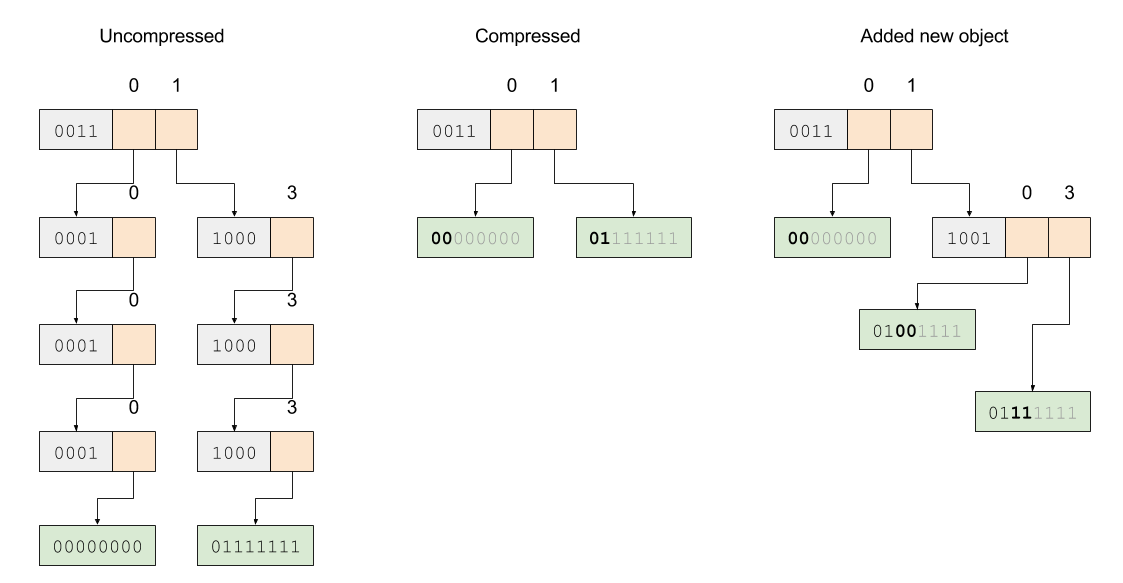 Trie Height Compression
Trie Height Compression
同理,在添加和删除新的对象的时候,我们还需要动态地维护树的高度,在合适的时候增加或者减少树的高度。 最右边的图展示了在 Hash Table 中插入 79(01 00 11 11)之后 Trie 树的结构。可以看到, 因为新的节点插入,最高位01两个比特位指代的对象出现了混淆,不能唯一地确定一个对象, 因此我们要进一步地利用剩下的比特位来构造无混淆的树。
由于对 Trie 的各种操作都是基于树上节点的访问,对 Trie 高度进行的压缩不单节约了内存空间, 也提高了查询和访问的性能。
基本操作的实现
在熟悉了 HAMT 在原始的 Trie 表示上做了哪些优化之后,我们就可以给出在 HAMT 实现的 Hash Table 上进行各种操作的基本思路了。
查询操作
查询操作和在 Trie 上进行查询没有太大的改变,只是因为节点的空间被压缩之后,需要先通过 Bit Map 字段 判断对应的位置是否存在子元素,如果存在,再通过 Pop Count 计算得到子元素所在的实际位置。 在获得到子元素之后,鉴于 HAMT 对 Trie 的高度进行了压缩,我们要先判断这个子元素是 Trie 的子节点还是值元素本身。对于 Hash Table,我们将值包装成<Key, Value>这样的一个值节点存放进去。 这样取出时就可以先判断 Key 的值是否相同,以此决定是否真的取到了对象。
加入操作
加入操作类似于查询操作,对于给定的键值对,我们先计算键的 Hash 值,然后从高位开始利用 Hash 值。 沿着 Trie 树向下查找,此时存在四种情况:
- 查找到一个位置,这个位置所保存的值对象代表的键和新插入的键相同,则用新插入的值代替原来的值
- 查找到一个子节点,这个子节点再向下目标对象应该所在的位置没有元素,此时只需申请一个新的宽度比当前子节点多1的节点, 将原来子节点上的所有元素连带当前对象一一设置到新的子节点上,维护好元素的顺序和 Bit Map 的值即可
- 查找到一个子节点,这个子节点再向下目标对象所应该在的位置是一个值对象,这时,为这个值对象连带当前对象分配一个宽度为2 的子节点,将原来的值对象和当前对象放置在新的节点中,最后用新的节点在当前子节点中替换掉对应位置
- 查找到一个子节点,这个节点再向下目标对象所应该在的位置是另一个子节点,则在那个子节点上递归进行上述操作
在以上三种情况外,还有一种情况即为出现 Hash 值碰撞。也就是说,当前想要插入的值和 Hash Table 当中某一个对象的 Hash 值完全一样,这样即使两个对象的 Hash 值全部用尽,也无法不混淆地存放两个对象。这时就需要进行碰撞处理。 对于 HAMT 来说,常见的碰撞处理有些类似于加盐 Hash 的过程。理论上来说,一个良好设计的 Hash 函数本身的碰撞概率就极小, 如果两个元素确实在某次计算中 Hash 碰撞,在两个元素上追加某段已知的固定数据,再进行 Hash 所得的结果极有可能不再碰撞。 因此我们可以利用这一特点,当两个对象 Hash 值相同,我们追加一个值,再进行一次 Hash,利用得到的新 Hash 值接着在 Trie 上执行插入即可。
如果出现了两个不同的对象,无论怎么 Hash ,都得到一样的值,那么要么表明使用 Hash 函数本身是有问题的, 要么说明容器的实现存在问题。这时就应该直接报错了。
删除操作
删除操作是加入操作的逆运算,其基本原理也类似。在删除时,现在 Trie 中找到对应的对象,然后依次递归地删除。 在从子节点删除一个元素时,我们也一样要分配一个新的子节点,这个子节点的宽度比原来少1。 之后将剩余的子元素按照规则放回新的子节点并维护 Bit Map 字段的值。最后用新的子节点替换原来的节点并递归向上进行。 一般来讲,在递归时有如下几个情况:
- 在子节点进行删除操作之后,子节点不再包含任何子元素,则删除当前子节点并返回空
- 当前子节点只剩下一个元素,且这个元素为值元素,则应该降低树的高度,直接返回值元素
- 当前子节点只剩下一个元素,且这个元素是子节点,则保留这个子节点,回到上一个节点
持久化 HAMT
由于 HAMT 本质上还是 Trie,因此我们可以按照之前 Vector Trie 一样的策略来实现持久化。 简单来说还是在需要修改节点时,不对原来的节点进行直接的修改,而是生成新节点并复制节点到根的路径。 同样,通过在节点中添加 id 字段,我们也可以在 HAMT 上实现 Transient 以加快批量操作的速度。
总结
在按照上述介绍的空间压缩方法和 Trie 操作方法实现了 HAMT 之后,还有一些问题需要注意:
- 从算法分析上来讲,HAMT 的各项操作时间复杂度都在常数级别内,但是如前文所提,仍需要注意 Pop Count 等操作的时间花费,尽量针对不同平台选用性能最高的实现方案
- HAMT 不像传统的 Hash Table 那样集中地分配大量空间,而是在每次加入和删除时重新生成子节点并分配小块的空间, 因此内存申请的时间花费在这里不可以被忽略。事实上,Benchmark 表明 HAMT 的一般实现当中内存管理花费的时间是最显著的。 在这种情况下,由容器自己维护一个内存池是必要的。也就是说,在每次生成新的节点时,并不直接申请新的内存, 而是先从内存池当中尝试获取一个目标宽度的子节点。同理,在释放一个子节点的时候也是将节点返回给这一内存池。 线程安全的内存池的实现又是另外一个巨大的主题了,这里也不再赘述
- HAMT 的设计是针对像 C 或 C++ 这样完面向内存、可以细力度控制数据结构在内存中布局的编程语言设计的, 因此在 JVM 和 Golang 这种比较远离硬件的编程语言上进行实现,内存的痕迹和操作的性能均可能不能达到真正的理想状态。 近期有一篇名为 Optimizing Hash-Array Mapped Tries for Fast and Lean Immutable JVM Collections 的论文讨论了在 JVM 上优化 HAMT 的实现,有兴趣的读者可以进一步阅读。