概念
什么是Hive
Hive是基于Apache Hadoop的数据仓库基础架构。Hadoop为商品硬件上的数据存储和处理提供了大规模的横向扩展和容错功能。
Hive旨在简化数据汇总,临时查询和分析大量数据的过程。它提供了SQL,使用户可以轻松地进行即席查询,摘要和数据分析。同时,Hive的SQL为用户提供了多个位置,以集成他们自己的功能以进行自定义分析,例如用户定义函数(UDF)。
Hive不是什么
Hive不适用于在线交易处理。 最佳用于传统数据仓库任务。
入门
有关设置Hive,HiveServer2和直线的详细信息,请参阅 GettingStarted指南。
有关Hive的书籍列出了一些可能对Hive入门也很有帮助的书籍。
在以下各节中,我们提供有关系统功能的教程。我们首先描述数据类型,表和分区的概念(与传统的关系型DBMS中的概念非常相似),然后借助一些示例来说明Hive的功能。
数据单位
按粒度顺序-Hive数据组织为:
- 数据库:命名空间的作用是避免表,视图,分区,列等的命名冲突。数据库还可以用于对一个用户或一组用户强制实施安全性。
- 表格:具有相同架构的同类数据单元。一个表的示例可以是page_views表,其中每一行可以包含以下列(模式):
timestamp—属于INT类型,与查看该页面的UNIX时间戳相对应。userid—是BIGINT类型,用于标识查看该页面的用户。page_url—属于STRING类型,用于捕获页面的位置。referer_url—其中STRING个可捕获用户到达当前页面的页面位置。IP—属于STRING类型,用于捕获发出页面请求的IP地址。
- 分区:每个表可以具有一个或多个分区键,这些键确定数据的存储方式。分区-除了作为存储单元-还允许用户有效地标识满足指定条件的行;例如,类型为STRING的date_partition和类型为STRING的country_partition。分区键的每个唯一值定义表的一个分区。例如,来自“ 2009-12-23”的所有“ US”数据都是page_views表的分区。因此,如果仅对2009-12-23的“美国”数据运行分析,则可以仅对表的相关分区运行该查询,从而大大加快了分析速度。但是请注意,仅因为分区名为2009-12-23并不意味着该分区包含该日期之后的全部或仅数据。为方便起见,分区以日期命名;保证分区名称和数据内容之间的关系是用户的工作!分区列是虚拟列,
- 存储桶(或群集):每个分区中的数据又可以根据表中某些列的哈希函数的值分为存储桶。例如,page_views表可以按userid进行存储,userid是page_view表中除分区列之外的列之一。这些可用于有效采样数据。
请注意,不必对表进行分区或存储,但是这些抽象使系统可以在查询处理期间修剪大量数据,从而加快查询执行速度。
类型系统
Hive支持原始和复杂的数据类型,如下所述。有关其他信息,请参见Hive数据类型。
基本类型
- 类型与表中的列关联。支持以下基本类型:
- 整数
- TINYINT — 1个字节的整数
- SMALLINT — 2字节整数
- INT — 4字节整数
- BIGINT — 8字节整数
- 布尔型
- 布尔- TRUE / FALSE
- 浮点数字
- FLOAT -单精度
- 双倍—双精度
- 定点数
- DECIMAL —用户定义的比例和精度的固定点值
- 字符串类型
- STRING —指定字符集中的字符序列
- VARCHAR —指定字符集中最大长度的字符序列
- CHAR —具有定义长度的指定字符集中的字符序列
- 日期和时间类型
- TIMESTAMP —不带时区的日期和时间(“ LocalDateTime”语义)
- 带有本地时区的时间戳 —精确到纳秒的时间点(“即时”语义)
- DATE -日期
- 二进制类型
- BINARY —字节序列
这些类型按以下层次结构进行组织(其中父级是所有子级实例的超类型):
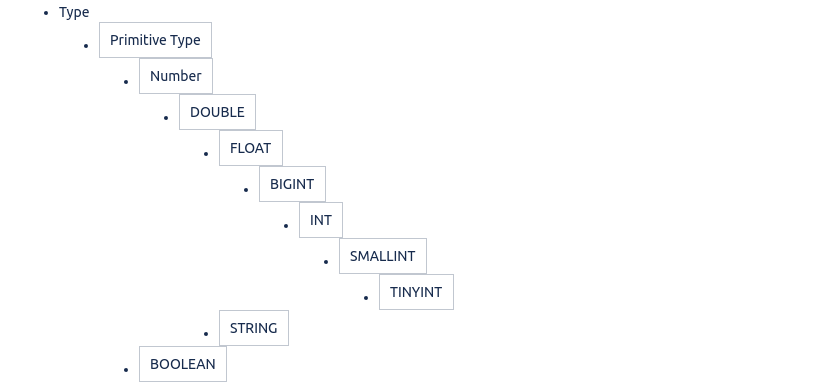
此类型层次结构定义如何在查询语言中隐式转换类型。允许从子类型到祖先类型的隐式转换。因此,当查询表达式期望类型为1且数据类型为2时,如果类型1是类型层次结构中类型2的祖先,则类型2将隐式转换为类型1。请注意,类型层次结构允许将STRING隐式转换为DOUBLE。
可以使用强制转换运算符来进行显式类型转换,如下面的“ 内置函数”部分所示。
复杂类型
可以使用以下方法从原始类型和其他组合类型中构建复杂类型:
- 结构:可以使用DOT(。)表示法访问类型内的元素。例如,对于类型STRUCT {a INT; b INT},则表达式ca访问a字段
- 映射(键值元组):使用['element name']表示法访问元素。例如,在包含从'group'-> gid的映射组成的映射M中,可以使用M ['group']访问gid值
- 数组(可索引列表):数组中的元素必须具有相同的类型。可以使用[n]表示法访问元素,其中n是数组的索引(从零开始)。例如,对于具有元素['a','b','c']的数组A,A [1]重新运行'b'。
使用原始类型和用于创建复杂类型的构造,可以创建具有任意嵌套级别的类型。例如,用户类型可以包含以下字段:
- 性别-这是STRING。
- 活跃的-这是BOOLEAN。
时间戳
时间戳一直是造成混乱的根源,因此我们尝试记录Hive的预期语义。
时间戳(“ LocalDateTime”语义)
Java的“ LocalDateTime”时间戳将日期和时间记录为年,月,日,时,分和秒,没有时区。无论本地时区如何,这些时间戳始终具有相同的值。
例如,时间戳值“ 2014-12-12 12:34:56”被分解为年,月,日,小时,分钟和秒字段,但是没有可用的时区信息。它不对应于任何特定时刻。无论本地时区如何,它将始终是相同的值。除非您的应用程序始终使用UTC,否则对于大多数应用程序,时间戳优先于本地时区。当用户说某个事件是在10:00时,它始终是相对于某个时区的,它表示一个时间点,而不是任意时区中的10:00。
具有本地时区的时间戳(“即时”语义)
Java的“即时”时间戳定义了一个恒定的时间点,无论从何处读取数据。因此,时间戳将通过本地时区进行调整以匹配原始时间点。
| Type | Value in America/Los_Angeles | Value in America/New_York |
|---|---|---|
| Type | Value in America/Los_Angeles | Value in America/New_York |
| timestamp | 2014-12-12 12:34:56 | 2014-12-12 12:34:56 |
| timestamp with local time zone | 2014-12-12 12:34:56 | 2014-12-12 15:34:56 |
与其他工具的比较
| SQL 2003 | Oracle | Sybase | Postgres | MySQL | Microsoft SQL | IBM DB2 | Presto | Snowflake | Hive >= 3.1 | Iceberg | Spark | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SQL 2003 | Oracle | Sybase | Postgres | MySQL | Microsoft SQL | IBM DB2 | Presto | Snowflake | Hive >= 3.1 | Iceberg | Spark | |
| timestamp | Local | Local | Local | Local | Instant | Other | Local | Local | Local | Local | Local | Instant |
| timestamp with local time zone | Instant | Instant | Instant | |||||||||
| timestamp with time zone | Offset | Offset | Offset | Instant | Offset | Offset | Offset | Instant | ||||
| timestamp without time zone | Local | Local | Local | Local |
其他定义:
- Offset=记录时间点以及编写者所在时区中的时区偏移量。
内置的运算符和功能
下面列出的运算符和功能不一定是最新的。(Hive Operators和UDF具有更多当前信息。)在Beeline或Hive CLI中,使用以下命令显示最新文档:
SHOW FUNCTIONS;DESCRIBE FUNCTION <function_name>;DESCRIBE FUNCTION EXTENDED <function_name>; |
不区分大小写
所有Hive关键字都不区分大小写,包括Hive运算符和函数的名称。
内置运算符
- 关系运算符-以下运算符比较传递的操作数并生成TRUE或FALSE值,具体取决于操作数之间的比较是否成立。
| 关系运算符 | 操作数类型 | 描述 |
|---|---|---|
| 关系运算符 | 操作数类型 | 描述 |
| A = B | 所有原始类型 | 如果表达式A等于表达式B,则为TRUE;否则为。否则为FALSE |
| A!= B | 所有原始类型 | 如果表达式A 不等于表达式B,则为TRUE;否则为。否则为FALSE |
| A <B | 所有原始类型 | 如果表达式A小于表达式B,则为TRUE;否则为。否则为FALSE |
| A <= B | 所有原始类型 | 如果表达式A小于或等于表达式B,则为TRUE;否则为。否则为FALSE |
| A> B | 所有原始类型 | 如果表达式A大于表达式B,则为TRUE,否则为FALSE |
| A> = B | 所有原始类型 | 如果表达式A大于或等于表达式B,则为TRUE,否则为FALSE |
| A IS NULL | 所有类型 | 如果表达式A的计算结果为NULL,则为TRUE,否则为FALSE |
| A IS NOT NULL | 所有类型 | 如果表达式A的计算结果为NULL,则为FALSE,否则为TRUE |
| A LIKE B | strings | 如果字符串A与SQL简单正则表达式B匹配,则为TRUE,否则为FALSE。逐个字符进行比较。在B中的_字符与所述的任何字符(类似于。在POSIX正则表达式),和B中的%字符的字符中所述的任意数量的匹配(相似。*在POSIX正则表达式)。例如,'foobar' LIKE 'foo'对FALSE 'foobar' LIKE 'foo___'求值,而对TRUE求值,对'foobar' LIKE 'foo%'。要转义%,请使用\(%匹配一个%字符)。如果数据包含分号,并且您要搜索,则需要转义,columnValue LIKE 'a\;b' |
| A RLIKE B | strings | 如果A或B为NULL,则为NULL,如果A的任何子字符串(可能为空)与Java正则表达式B匹配(请参见Java正则表达式语法),则为TRUE ,否则为FALSE。例如,'foobar'rlike'foo'的计算结果为TRUE,'foobar'rlike'^ f。* r $'的计算结果也为TRUE。 |
| A REGEXP B | strings | 与RLIKE相同 |
- 算术运算符—以下运算符支持对操作数的各种常见算术运算。它们都返回数字类型。
| 算术运算符 | 操作数类型 | 描述 |
|---|---|---|
| 算术运算符 | 操作数类型 | 描述 |
| A + B | 所有数字类型 | 给出将A和B相加的结果。结果的类型与操作数类型的公共父级(在类型层次结构中)相同,例如,因为每个整数都是浮点数。因此,float是整数的包含类型,因此float和int上的+运算符将导致float。 |
| A-B | 所有数字类型 | 给出从A减去B的结果。结果的类型与操作数类型的公共父级(在类型层次结构中)相同。 |
| A * B | 所有数字类型 | 给出将A和B相乘的结果。结果的类型与操作数类型的公共父级(在类型层次结构中)相同。请注意,如果乘法导致溢出,则必须将其中一个运算符转换为类型层次结构中较高的类型。 |
| A / B | 所有数字类型 | 给出从A除以B的结果。结果的类型与操作数类型的公共父级(在类型层次结构中)相同。如果操作数是整数类型,则结果是除法的商。 |
| A%B | 所有数字类型 | 给出A除以B的结果。结果的类型与操作数类型的公共父级(在类型层次结构中)相同。 |
| A&B | 所有数字类型 | 给出A和B的按位与的结果。结果的类型与操作数类型的公共父级(在类型层次结构中)相同。 |
| A | B | 所有数字类型 | 给出A和B的按位或的结果。结果的类型与操作数类型的公共父级(在类型层次结构中)相同。 |
| A ^ B | 所有数字类型 | 给出A和B的按位XOR结果。结果的类型与操作数类型的公共父级(在类型层次结构中)相同。 |
| 〜A | 所有数字类型 | 给出A的按位NOT的结果。结果的类型与A的类型相同。 |
- 逻辑运算符 -以下运算符为创建逻辑表达式提供支持。它们都根据操作数的布尔值返回布尔值TRUE或FALSE。
| 逻辑运算符 | 操作数类型 | 描述 |
|---|---|---|
| 逻辑运算符 | Operands types | Description |
| A AND B | 布尔值 | 如果A和B均为TRUE,则为TRUE,否则为FALSE |
| A && B | 布尔值 | 与A和B相同 |
| A OR B | 布尔值 | 如果A或B或两者均为TRUE,则为TRUE,否则为FALSE |
| A || B | 布尔值 | 与A或B相同 |
| NOT A | 布尔值 | 如果A为FALSE,则为TRUE,否则为FALSE |
| !A | 布尔值 | 与NOT A相同 |
- 复杂类型上的运算符—以下运算符提供了访问复杂类型上的元素的机制
| 操作员 | 操作数类型 | 描述 |
|---|---|---|
| 操作员 | 操作数类型 | 描述 |
| A[n] | A是一个数组,n是一个整数 | 返回数组A中的第n个元素。第一个元素的索引为0,例如,如果A是包含['foo','bar']的数组,则A [0]返回'foo',而A [1]返回'酒吧' |
| M[key] | M是Map <K,V>并且键的类型为K | 例如,如果M是包含{'f'->'foo','b'->'bar','all'->'foobar'} 的映射,则返回M ['all']返回'foobar' |
| S.x | S是一个结构 | 返回S的x字段,例如,对于struct foobar {int foo,int bar} foobar.foo返回存储在struct的foo字段中的整数。 |
内置功能
- Hive支持以下内置函数:(
源代码中的函数列表:FunctionRegistry.java)
| Return Type | Function Name (Signature) | Description |
|---|---|---|
| Return Type | Function Name (Signature) | Description |
| BIGINT | round(double a) | returns the rounded BIGINT value of the double |
| BIGINT | floor(double a) | returns the maximum BIGINT value that is equal or less than the double |
| BIGINT | ceil(double a) | returns the minimum BIGINT value that is equal or greater than the double |
| double | rand(), rand(int seed) | returns a random number (that changes from row to row). Specifiying the seed will make sure the generated random number sequence is deterministic. |
| string | concat(string A, string B,...) | returns the string resulting from concatenating B after A. For example, concat('foo', 'bar') results in 'foobar'. This function accepts arbitrary number of arguments and return the concatenation of all of them. |
| string | substr(string A, int start) | returns the substring of A starting from start position till the end of string A. For example, substr('foobar', 4) results in 'bar' |
| string | substr(string A, int start, int length) | returns the substring of A starting from start position with the given length, for example, substr('foobar', 4, 2) results in 'ba' |
| string | upper(string A) | returns the string resulting from converting all characters of A to upper case, for example, upper('fOoBaR') results in 'FOOBAR' |
| string | ucase(string A) | Same as upper |
| string | lower(string A) | returns the string resulting from converting all characters of B to lower case, for example, lower('fOoBaR') results in 'foobar' |
| string | lcase(string A) | Same as lower |
| string | trim(string A) | returns the string resulting from trimming spaces from both ends of A, for example, trim(' foobar ') results in 'foobar' |
| string | ltrim(string A) | returns the string resulting from trimming spaces from the beginning(left hand side) of A. For example, ltrim(' foobar ') results in 'foobar ' |
| string | rtrim(string A) | returns the string resulting from trimming spaces from the end(right hand side) of A. For example, rtrim(' foobar ') results in ' foobar' |
| string | regexp_replace(string A, string B, string C) | returns the string resulting from replacing all substrings in B that match the Java regular expression syntax(See Java regular expressions syntax) with C. For example, regexp_replace('foobar', 'oo|ar', ) returns 'fb' |
| int | size(Map<K.V>) | returns the number of elements in the map type |
| int | size(Array | returns the number of elements in the array type |
| value of | cast( | converts the results of the expression expr to |
| string | from_unixtime(int unixtime) | convert the number of seconds from the UNIX epoch (1970-01-01 00:00:00 UTC) to a string representing the timestamp of that moment in the current system time zone in the format of "1970-01-01 00:00:00" |
| string | to_date(string timestamp) | Return the date part of a timestamp string: to_date("1970-01-01 00:00:00") = "1970-01-01" |
| int | year(string date) | Return the year part of a date or a timestamp string: year("1970-01-01 00:00:00") = 1970, year("1970-01-01") = 1970 |
| int | month(string date) | Return the month part of a date or a timestamp string: month("1970-11-01 00:00:00") = 11, month("1970-11-01") = 11 |
| int | day(string date) | Return the day part of a date or a timestamp string: day("1970-11-01 00:00:00") = 1, day("1970-11-01") = 1 |
| string | get_json_object(string json_string, string path) | Extract json object from a json string based on json path specified, and return json string of the extracted json object. It will return null if the input json string is invalid. |
语言能力
Hive的SQL提供了基本的SQL操作。这些操作适用于表或分区。这些操作是:
- 能够使用WHERE子句从表中过滤行。
- 可以使用SELECT子句从表中选择某些列。
- 在两个表之间进行等值联接的能力。
- 能够针对表中存储的数据评估多个“ group by”列上的聚合。
- 能够将查询结果存储到另一个表中。
- 能够将表的内容下载到本地(例如,nfs)目录。
- 能够将查询结果存储在hadoop dfs目录中。
- 能够管理表和分区(创建,删除和更改)。
- 能够以自定义地图/缩小作业选择的语言插入自定义脚本。
用法与范例
**注意:以下许多示例已过时。在LanguageManual中可以找到更多最新信息 。 **
以下示例突出了系统的一些显着功能。详细的查询测试用例集可以在Hive查询测试用例中找到,相应的结果可以在查询测试用例结果中找到。
/<![CDATA[/ div.rbtoc1594295362251 {padding: 0px;} div.rbtoc1594295362251 ul {list-style: disc;margin-left: 0px;} div.rbtoc1594295362251 li {margin-left: 0px;padding-left: 0px;} /]]>/
创建,显示,更改和删除表
有关创建,显示,更改和删除表的详细信息,请参见Hive数据定义语言。
建立表格
创建上面提到的page_view表的示例语句如下所示:
CREATE TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT 'IP Address of the User')COMMENT 'This is the page view table'PARTITIONED BY(dt STRING, country STRING)STORED AS SEQUENCEFILE; |
在此示例中,使用相应的类型指定表的列。注释可以附加在列级和表级。此外,partitioned by子句定义的分区列与数据列不同,实际上并未与数据一起存储。以这种方式指定时,假定文件中的数据使用ASCII 001(ctrl-A)作为字段定界符,使用换行符作为行定界符来定界。
如果数据不是上述格式的数据,则可以对字段定界符进行参数设置,如下例所示:
CREATE TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT 'IP Address of the User')COMMENT 'This is the page view table'PARTITIONED BY(dt STRING, country STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '1'STORED AS SEQUENCEFILE; |
由于行分隔符不是由Hive而是由Hadoop分隔符确定,因此当前无法更改行分隔符。
将表存储在某些列上也是一个好主意,以便可以针对数据集执行有效的采样查询。如果没有存储分区,仍然可以在表上进行随机采样,但是效率不高,因为查询必须扫描所有数据。以下示例说明了在userid列上存储的page_view表的情况:
CREATE TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT 'IP Address of the User')COMMENT 'This is the page view table'PARTITIONED BY(dt STRING, country STRING)CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETSROW FORMAT DELIMITED FIELDS TERMINATED BY '1' COLLECTION ITEMS TERMINATED BY '2' MAP KEYS TERMINATED BY '3'STORED AS SEQUENCEFILE; |
在上面的示例中,该表通过userid的哈希函数聚集到32个存储桶中。在每个存储桶中,数据按viewTime的升序排序。这样的组织允许用户在聚集列上进行高效采样-在这种情况下为用户ID。排序属性允许内部运算符在更好地评估查询的同时利用众所周知的数据结构。
CREATE TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, friends ARRAY<BIGINT>, properties MAP<STRING, STRING> ip STRING COMMENT 'IP Address of the User')COMMENT 'This is the page view table'PARTITIONED BY(dt STRING, country STRING)CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETSROW FORMAT DELIMITED FIELDS TERMINATED BY '1' COLLECTION ITEMS TERMINATED BY '2' MAP KEYS TERMINATED BY '3'STORED AS SEQUENCEFILE; |
在此示例中,以与类型定义类似的方式指定组成表行的列。注释可以附加在列级和表级。此外,partitioned by子句定义的分区列与数据列不同,实际上并未与数据一起存储。CLUSTERED BY子句指定用于存储桶的列以及要创建的存储桶数。分隔行格式指定行如何在配置单元表中存储。在定界格式的情况下,这指定了字段的终止方式,集合(数组或映射)中的项目的终止方式以及映射键的终止方式。STORED AS SEQUENCEFILE表示此数据以二进制格式(使用hadoop SequenceFiles)存储在hdfs上。
表名和列名不区分大小写。
浏览表和分区
SHOW TABLES; |
列出仓库中的现有表;其中有很多,可能比您想要浏览的更多。
SHOW TABLES 'page.*'; |
列出前缀为“ page”的表。该模式遵循Java正则表达式语法(因此句点是通配符)。
SHOW PARTITIONS page_view; |
列出表分区。如果该表不是分区表,则将引发错误。
DESCRIBE page_view; |
列出表的列和列类型。
DESCRIBE EXTENDED page_view; |
列出表的列和所有其他属性。这会打印很多信息,但也不会以漂亮的格式显示。通常用于调试。
DESCRIBE EXTENDED page_view PARTITION (ds='2008-08-08'); |
列出分区的列和所有其他属性。这还会打印很多通常用于调试的信息。
修改表
将现有表重命名为新名称。如果具有新名称的表已经存在,则返回错误:
ALTER TABLE old_table_name RENAME TO new_table_name; |
重命名现有表的列。确保使用相同的列类型,并为每个现有列包括一个条目:
ALTER TABLE old_table_name REPLACE COLUMNS (col1 TYPE, ...); |
要将列添加到现有表:
ALTER TABLE tab1 ADD COLUMNS (c1 INT COMMENT 'a new int column', c2 STRING DEFAULT 'def val'); |
请注意,架构的更改(例如添加列)会在表是分区表的情况下保留表的旧分区的架构。所有访问这些列并在旧分区上运行的查询都隐式地为这些列返回空值或指定的默认值。
在以后的版本中,我们可以使假设某些值的行为与在特定分区中未找到该列的情况下抛出错误相反。
删除表和分区
删除表相当简单。将该表放下将隐式删除该表上已建立的所有索引(这是将来的功能)。关联的命令是:
DROP TABLE pv_users; |
删除分区。更改表以删除分区。
ALTER TABLE pv_users DROP PARTITION (ds='2008-08-08') |
- 请注意,此表或分区的任何数据将被删除并且可能无法恢复。*
加载数据中
有多种方法可以将数据加载到Hive表中。用户可以创建一个指向HDFS中指定位置的外部表。在这种特定用法中,用户可以使用HDFS放置或复制命令将文件复制到指定位置,并创建一个指向该位置的表以及所有相关的行格式信息。完成此操作后,用户可以转换数据并将其插入任何其他Hive表中。例如,如果文件/tmp/pv_2008-06-08.txt包含2008年6月8日提供的用逗号分隔的页面视图,并且需要将其加载到适当分区中的page_view表中,则可以按照以下命令顺序进行操作实现这一目标:
CREATE EXTERNAL TABLE page_view_stg(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT 'IP Address of the User', country STRING COMMENT 'country of origination')COMMENT 'This is the staging page view table'ROW FORMAT DELIMITED FIELDS TERMINATED BY '44' LINES TERMINATED BY '12'STORED AS TEXTFILELOCATION '/user/data/staging/page_view';hadoop dfs -put /tmp/pv_2008-06-08.txt /user/data/staging/page_viewFROM page_view_stg pvsINSERT OVERWRITE TABLE page_view PARTITION(dt='2008-06-08', country='US')SELECT pvs.viewTime, pvs.userid, pvs.page_url, pvs.referrer_url, null, null, pvs.ipWHERE pvs.country = 'US'; |
*由于LINES TERMINATED BY限制,此代码导致错误
失败:SemanticException 6:67终止符行现在仅支持换行符'\ n'。令牌“ 12”附近遇到错误
看到 HIVE-5999 - 允许其他字符TERMINATED由线 打开
HIVE-11996 - 行分隔符不是'\ n'其他抛出Hive错误。 打开
在上面的示例中,在目标表中为数组和映射类型插入了空值,但如果指定了正确的行格式,则它们也可能来自外部表。
如果HDFS中已经存在旧数据,用户想要在其中放置一些元数据,以便可以使用Hive查询和操作该数据,则此方法很有用。
此外,系统还支持语法,可以将本地文件系统中文件中的数据直接加载到Hive表中,其中输入数据格式与表格式相同。如果/tmp/pv_2008-06-08_us.txt已经包含美国的数据,则我们不需要任何其他过滤,如上例所示。在这种情况下,可以使用以下语法完成加载:
LOAD DATA LOCAL INPATH /tmp/pv_2008-06-08_us.txt INTO TABLE page_view PARTITION(date='2008-06-08', country='US') |
path参数可以使用目录(在这种情况下,将加载目录中的所有文件),单个文件名或通配符(在这种情况下,将所有匹配的文件上载)。如果参数是一个目录,则它不能包含子目录。同样,通配符必须仅与文件名匹配。
如果输入文件/tmp/pv_2008-06-08_us.txt非常大,则用户可以决定对数据进行并行加载(使用Hive外部的工具)。将文件放入HDFS后,可以使用以下语法将数据加载到Hive表中:
LOAD DATA INPATH '/user/data/pv_2008-06-08_us.txt' INTO TABLE page_view PARTITION(date='2008-06-08', country='US') |
对于这些示例,假设input.txt文件中的array和map字段为空字段。
有关将数据加载到Hive表中的更多信息,请参见Hive数据操作语言;有关创建外部表的另一个示例,请参见外部表。
查询和插入数据
/<![CDATA[/ div.rbtoc1594295362265 {padding: 0px;} div.rbtoc1594295362265 ul {list-style: disc;margin-left: 0px;} div.rbtoc1594295362265 li {margin-left: 0px;padding-left: 0px;} /]]>/
Hive查询操作记录在Select中,而插入操作记录在将数据从查询插入Hive表和从查询将数据写入文件系统中。
简单查询
对于所有活动用户,可以使用以下形式的查询:
INSERT OVERWRITE TABLE user_activeSELECT user.*FROM userWHERE user.active = 1; |
请注意,与SQL不同,我们总是将结果插入表中。稍后我们将说明用户如何检查这些结果,甚至将其转储到本地文件中。您还可以在Beeline 或Hive CLI中运行以下查询 :
SELECT user.*FROM userWHERE user.active = 1; |
这将在内部重写为一些临时文件,并显示在Hive客户端。
基于分区的查询
系统根据分区列上的where子句条件自动确定要在查询中使用的分区。例如,为了获取域xyz.com引用的03/2008月份的所有page_views,可以编写以下查询:
INSERT OVERWRITE TABLE xyz_com_page_viewsSELECT page_views.*FROM page_viewsWHERE page_views.date >= '2008-03-01' AND page_views.date <= '2008-03-31' AND page_views.referrer_url like '%xyz.com'; |
请注意,此处使用page_views.date,因为该表(上面)是使用PARTITIONED BY(date DATETIME,country STRING)定义的;如果您给分区命名不同,请不要期望.date发挥您的想法!
加入
为了获得2008年3月3日page_view的人口统计细分(按性别),需要在userid列上连接page_view表和user表。如下面的查询所示,这可以通过联接来完成:
INSERT OVERWRITE TABLE pv_usersSELECT pv.*, u.gender, u.ageFROM user u JOIN page_view pv ON (pv.userid = u.id)WHERE pv.date = '2008-03-03'; |
为了进行外部联接,用户可以使用LEFT OUTER,RIGHT OUTER或FULL OUTER关键字限定联接,以指示外部联接的类型(保留的左侧,保留的右侧或两侧保留)。例如,为了在上面的查询中进行完全外部联接,相应的语法应类似于以下查询:
INSERT OVERWRITE TABLE pv_usersSELECT pv.*, u.gender, u.ageFROM user u FULL OUTER JOIN page_view pv ON (pv.userid = u.id)WHERE pv.date = '2008-03-03'; |
为了检查另一个表中是否存在键,用户可以使用LEFT SEMI JOIN,如以下示例所示。
INSERT OVERWRITE TABLE pv_usersSELECT u.*FROM user u LEFT SEMI JOIN page_view pv ON (pv.userid = u.id)WHERE pv.date = '2008-03-03'; |
为了联接多个表,用户可以使用以下语法:
INSERT OVERWRITE TABLE pv_friendsSELECT pv.*, u.gender, u.age, f.friendsFROM page_view pv JOIN user u ON (pv.userid = u.id) JOIN friend_list f ON (u.id = f.uid)WHERE pv.date = '2008-03-03'; |
请注意,Hive仅支持等联接。另外,最好将最大的表放在连接的最右侧,以获取最佳性能。
集合体
为了按性别计算不同用户的数量,可以编写以下查询:
INSERT OVERWRITE TABLE pv_gender_sumSELECT pv_users.gender, count (DISTINCT pv_users.userid)FROM pv_usersGROUP BY pv_users.gender; |
可以同时进行多个聚合,但是任何两个聚合都不能具有不同的DISTINCT列。例如,尽管以下可能
INSERT OVERWRITE TABLE pv_gender_aggSELECT pv_users.gender, count(DISTINCT pv_users.userid), count(*), sum(DISTINCT pv_users.userid)FROM pv_usersGROUP BY pv_users.gender; |
但是,不允许以下查询
INSERT OVERWRITE TABLE pv_gender_aggSELECT pv_users.gender, count(DISTINCT pv_users.userid), count(DISTINCT pv_users.ip)FROM pv_usersGROUP BY pv_users.gender; |
多表/文件插入
聚合或简单选择的输出可以进一步发送到多个表中,甚至可以发送到hadoop dfs文件(然后可以使用hdfs实用程序对其进行操作)。例如,如果与性别细分一起,需要按年龄查找唯一页面浏览的细分,则可以通过以下查询来完成:
FROM pv_usersINSERT OVERWRITE TABLE pv_gender_sum SELECT pv_users.gender, count_distinct(pv_users.userid) GROUP BY pv_users.genderINSERT OVERWRITE DIRECTORY '/user/data/tmp/pv_age_sum' SELECT pv_users.age, count_distinct(pv_users.userid) GROUP BY pv_users.age; |
第一个insert子句将第一个group by的结果发送到Hive表,而第二个insert子句将结果发送到hadoop dfs文件。
动态分区插入
在前面的示例中,用户必须知道要插入哪个分区,并且只能在一个insert语句中插入一个分区。如果要加载到多个分区,则必须使用多插入语句,如下所示。
FROM page_view_stg pvsINSERT OVERWRITE TABLE page_view PARTITION(dt='2008-06-08', country='US') SELECT pvs.viewTime, pvs.userid, pvs.page_url, pvs.referrer_url, null, null, pvs.ip WHERE pvs.country = 'US'INSERT OVERWRITE TABLE page_view PARTITION(dt='2008-06-08', country='CA') SELECT pvs.viewTime, pvs.userid, pvs.page_url, pvs.referrer_url, null, null, pvs.ip WHERE pvs.country = 'CA'INSERT OVERWRITE TABLE page_view PARTITION(dt='2008-06-08', country='UK') SELECT pvs.viewTime, pvs.userid, pvs.page_url, pvs.referrer_url, null, null, pvs.ip WHERE pvs.country = 'UK'; |
为了将数据加载到特定日期的所有国家/地区分区中,您必须在输入数据中为每个国家/地区添加一条插入语句。这非常不方便,因为您必须先了解输入数据中存在的国家/地区列表,并事先创建分区。如果列表更改了另一天,则必须修改插入DML以及分区创建DDL。由于每个插入语句都可以转换为MapReduce作业,因此效率也不高。
动态分区插入(或多分区插入)旨在通过动态确定在扫描输入表时应创建和填充哪些分区来解决此问题。这是新增功能,仅从0.6.0版本开始可用。在动态分区插入中,将评估输入列的值,以确定应将此行插入哪个分区。如果尚未创建该分区,它将自动创建该分区。使用此功能,您只需一个插入语句即可创建并填充所有必要的分区。另外,由于只有一个insert语句,所以只有一个对应的MapReduce作业。与多次插入的情况相比,这可以显着提高性能并减少Hadoop集群的工作量。
以下是使用一个插入语句将数据加载到所有国家/地区分区的示例:
FROM page_view_stg pvsINSERT OVERWRITE TABLE page_view PARTITION(dt='2008-06-08', country) SELECT pvs.viewTime, pvs.userid, pvs.page_url, pvs.referrer_url, null, null, pvs.ip, pvs.country |
与多插入语句有一些语法差异:
- 国家/地区出现在PARTITION规范中,但没有关联的值。在这种情况下,country是动态分区列。另一方面,ds具有与其关联的值,这意味着它是静态分区列。如果列是动态分区列,则其值将来自输入列。当前,我们仅允许动态分区列成为partition子句中的最后一列,因为分区列顺序指示其层次结构顺序(意味着dt是根分区,而country是子分区)。您不能使用(dt,country ='US')指定分区子句,因为这意味着您需要使用任何日期更新所有分区,并且其国家子分区为'US'。
- 在select语句中添加了一个附加的pvs.country列。这是动态分区列的相应输入列。请注意,您不需要为静态分区列添加输入列,因为它的值在PARTITION子句中是已知的。请注意,动态分区值是通过排序而不是名称来选择的,并被用作select子句的最后一列。
动态分区插入语句的语义:
-
当动态分区列中已经存在非空分区时(例如,在某些ds根分区下存在country ='CA'),如果动态分区插入看到相同的值(例如'CA'),它将被覆盖。 )输入数据中。这符合“插入覆盖”的语义。但是,如果分区值“ CA”未出现在输入数据中,则现有分区将不会被覆盖。
-
由于Hive分区与HDFS中的目录相对应,因此分区值必须符合HDFS路径格式(Java中的URI)。URI中具有特殊含义的任何字符(例如'%',':','/','#')都将以'%'进行转义,后跟2个字节的ASCII值。
-
如果输入列的类型不同于STRING,则其值将首先转换为STRING以用于构造HDFS路径。
-
如果输入列的值为NULL或空字符串,则该行将被放入一个特殊分区,其名称由配置单元参数hive.exec.default.partition.name控制。默认值为
HIVE_DEFAULT_PARTITION{ }。基本上,该分区将包含其值不是有效分区名称的所有“坏”行。这种方法的警告是,如果您将它们选择为Hive ,则不良值将丢失,并由HIVE_DEFAULT_PARTITION{ *}*代替。JIRA HIVE-1309是一种允许用户指定“错误文件”以保留输入分区列值的解决方案。 -
动态分区插入可能会占用大量资源,因为它可能会在短时间内生成大量分区。为了使自己安全,我们定义了三个参数:
- hive.exec.max.dynamic.partitions.pernode(默认值为100)是每个映射器或化简器可以创建的最大动态分区。如果一个映射器或缩减器创建的阈值多于该阈值,则会从映射器/缩减器中引发致命错误(通过计数器),并且整个工作将被杀死。
- hive.exec.max.dynamic.partitions(默认值为1000)是一个DML可以创建的动态分区的总数。如果每个映射器/缩减器未超过限制,但动态分区的总数未超过限制,则在将中间数据移至最终目标之前,作业结束时会引发异常。
- hive.exec.max.created.files(默认值为100000)是所有映射器和化简器创建的最大文件总数。每当创建新文件时,每个映射器/还原器都会更新Hadoop计数器,从而实现此目的。如果总数超过hive.exec.max.created.files,将引发致命错误并杀死作业。
-
我们要防止动态分区插入的另一种情况是,用户可能无意中将所有分区指定为动态分区,而没有指定一个静态分区,而最初的意图是仅覆盖一个根分区的子分区。我们定义另一个参数hive.exec.dynamic.partition.mode = strict以防止出现全动态分区情况。在严格模式下,您必须至少指定一个静态分区。默认模式为严格模式。另外,我们有一个参数hive.exec.dynamic.partition = true / false来控制是否允许动态分区。Hive 0.9.0之前的默认值为false,Hive 0.9.0及更高版本的默认值为true。
-
在Hive 0.6中,动态分区插入不适用于hive.merge.mapfiles = true或hive.merge.mapredfiles = true,因此它在内部关闭了合并参数。Hive 0.7支持在动态分区插入中合并文件(有关详细信息,请参见JIRA HIVE-1307)。
故障排除和最佳实践:
-
如上所述,特定的映射器/缩减程序创建的动态分区过多,可能会引发致命错误,并且作业将被杀死。错误消息看起来像:
beeline> set hive.exec.dynamic.partition.mode=nonstrict;beeline> FROM page_view_stg pvsINSERT OVERWRITE TABLE page_view PARTITION(dt, country)SELECT pvs.viewTime, pvs.userid, pvs.page_url, pvs.referrer_url,null,null, pvs.ip,from_unixtimestamp(pvs.viewTime,'yyyy-MM-dd') ds, pvs.country;...2010-05-0711:10:19,816Stage-1map =0%, reduce =0%[Fatal Error] Operator FS_28 (id=41): fatal error. Killing the job.Ended Job = job_201005052204_28178 with errors...这样的问题是,一个映射器将随机获取一组行,并且不同的(dt,国家/地区)对的数量很可能会超过hive.exec.max.dynamic.partitions.pernode的限制。解决该问题的一种方法是按映射器中的动态分区列对行进行分组,然后将其分配到将创建动态分区的reducer。在这种情况下,不同动态分区的数量将大大减少。上面的示例查询可以重写为:
beeline> set hive.exec.dynamic.partition.mode=nonstrict;beeline> FROM page_view_stg pvsINSERT OVERWRITE TABLE page_view PARTITION(dt, country)SELECT pvs.viewTime, pvs.userid, pvs.page_url, pvs.referrer_url,null,null, pvs.ip,from_unixtimestamp(pvs.viewTime,'yyyy-MM-dd') ds, pvs.countryDISTRIBUTE BY ds, country;该查询将生成一个MapReduce作业,而不是仅Map作业。SELECT子句将转换为映射器的计划,并且输出将基于(ds,country)对的值分配给reduce。INSERT子句将在化简器中转换为计划,并写入动态分区。
附加文档:
插入本地文件
在某些情况下,您可能希望将输出写入本地文件,以便可以将其加载到excel电子表格中。这可以通过以下命令完成:
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/pv_gender_sum'SELECT pv_gender_sum.*FROM pv_gender_sum; |
采样
采样子句允许用户为数据样本而不是整个表编写查询。当前,采样是在CREATE TABLE语句的CLUSTERED BY子句中指定的列上完成的。在以下示例中,我们从pv_gender_sum表的32个存储桶中选择第三个存储桶:
INSERT OVERWRITE TABLE pv_gender_sum_sampleSELECT pv_gender_sum.*FROM pv_gender_sum TABLESAMPLE(BUCKET 3 OUT OF 32); |
通常,TABLESAMPLE语法如下所示:
TABLESAMPLE(BUCKET x OUT OF y) |
y必须是表创建时指定的表中存储桶数量的倍数或除数。如果bucket_number模块y等于x,则确定所选的桶。因此,在上面的示例中,以下tablesample子句
TABLESAMPLE(BUCKET 3 OUT OF 16) |
会挑选第三个和第19个桶。桶的编号从0开始。
另一方面,tablesample子句
TABLESAMPLE(BUCKET 3 OUT OF 64 ON userid) |
会从第三个桶中挑出一半。
联合所有
该语言还支持全部联合,例如,如果我们假设有两个不同的表来跟踪哪个用户发布了视频并且哪个用户发布了评论,则以下查询将全部联合的结果与user表结合起来以创建所有视频发布和评论发布事件的单个注释流:
INSERT OVERWRITE TABLE actions_usersSELECT u.id, actions.dateFROM ( SELECT av.uid AS uid FROM action_video av WHERE av.date = '2008-06-03' UNION ALL SELECT ac.uid AS uid FROM action_comment ac WHERE ac.date = '2008-06-03' ) actions JOIN users u ON(u.id = actions.uid); |
阵列运算
表中的数组列可以如下:
CREATE TABLE array_table (int_array_column ARRAY<INT>); |
假设pv.friends的类型为ARRAY
SELECT pv.friends[2]FROM page_views pv; |
选择表达式将获取pv.friends数组中的第三项。
用户还可以使用size函数获得数组的长度,如下所示:
SELECT pv.userid, size(pv.friends)FROM page_view pv; |
映射(关联数组)操作
映射提供类似于关联数组的集合。目前只能以编程方式创建此类结构。我们将尽快扩展。就当前示例而言,假定pv.properties的类型为map <String,String>,即它是从字符串到字符串的关联数组。相应地,以下查询:
INSERT OVERWRITE page_views_mapSELECT pv.userid, pv.properties['page type']FROM page_views pv; |
可用于从page_views表中选择“ page_type”属性。
与数组类似,size函数也可用于获取地图中的元素数,如以下查询所示:
SELECT size(pv.properties)FROM page_view pv; |
自定义映射/减少脚本
用户还可以使用Hive语言本身支持的功能,在数据流中插入自己的自定义映射器和简化器。例如,为了运行自定义映射器脚本map_script和自定义归约器脚本reduce_script,用户可以发出以下命令,该命令使用TRANSFORM子句嵌入映射器和归约器脚本。
请注意,在输入用户脚本之前,列将被转换为字符串并由TAB分隔,并且用户脚本的标准输出将被视为TAB分隔的字符串列。用户脚本可以将调试信息输出为标准错误,这将显示在hadoop的任务详细信息页面上。
FROM ( FROM pv_users MAP pv_users.userid, pv_users.date USING 'map_script' AS dt, uid CLUSTER BY dt) map_output INSERT OVERWRITE TABLE pv_users_reduced REDUCE map_output.dt, map_output.uid USING 'reduce_script' AS date, count; |
样例地图脚本(weekday_mapper.py)
import sysimport datetimefor line in sys.stdin: line = line.strip() userid, unixtime = line.split('\t') weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday() print ','.join([userid, str(weekday)]) |
当然,对于更一般的选择转换,MAP和REDUCE都是“语法糖”。内部查询也可以这样编写:
SELECT TRANSFORM(pv_users.userid, pv_users.date) USING 'map_script' AS dt, uid CLUSTER BY dt FROM pv_users; |
无模式映射/减少:如果在“ USING map_script”之后没有“ AS”子句,则Hive假定脚本的输出包含两部分:key在第一个选项卡之前,value则在第一个选项卡之后。请注意,这与指定“ AS键,值”不同,因为在这种情况下,如果存在多个选项卡,则值将仅包含第一个选项卡和第二个选项卡之间的部分。
这样,我们允许用户迁移旧的map / reduce脚本,而无需了解地图输出的架构。用户仍然需要知道reduce输出模式,因为它必须与我们要插入的表中的内容匹配。
FROM ( FROM pv_users MAP pv_users.userid, pv_users.date USING 'map_script' CLUSTER BY key) map_outputINSERT OVERWRITE TABLE pv_users_reduced REDUCE map_output.dt, map_output.uid USING 'reduce_script' AS date, count; |
分发方式和排序方式:用户可以指定“分发方式”和“排序方式”,而不是指定“群集方式”,因此分区列和排序列可以不同。通常的情况是分区列是排序列的前缀,但这不是必需的。
FROM ( FROM pv_users MAP pv_users.userid, pv_users.date USING 'map_script' AS c1, c2, c3 DISTRIBUTE BY c2 SORT BY c2, c1) map_outputINSERT OVERWRITE TABLE pv_users_reduced REDUCE map_output.c1, map_output.c2, map_output.c3 USING 'reduce_script' AS date, count; |
联合团体
在使用map / reduce的用户社区中,共同分组是一种相当常见的操作,其中将来自多个表的数据发送到自定义的约简器,以便按表中某些列的值对行进行分组。使用UNION ALL运算符和CLUSTER BY规范,可以通过以下方式在Hive查询语言中实现。假设我们想将uid列上的actions_video和action_comments表中的行进行分组,并将它们发送到'reduce_script'自定义reducer,则用户可以使用以下语法:
FROM ( FROM ( FROM action_video av SELECT av.uid AS uid, av.id AS id, av.date AS date UNION ALL FROM action_comment ac SELECT ac.uid AS uid, ac.id AS id, ac.date AS date ) union_actions SELECT union_actions.uid, union_actions.id, union_actions.date CLUSTER BY union_actions.uid) map INSERT OVERWRITE TABLE actions_reduced SELECT TRANSFORM(map.uid, map.id, map.date) USING 'reduce_script' AS (uid, id, reduced_val); |