MySQL死锁产生原因
所谓死锁
死锁的关键在于:两个(或以上)的Session加锁的顺序不一致。
那么对应的解决死锁问题的关键就是:让不同的session加锁有次序。
mysql如何避免死锁
https://www.pianshen.com/article/7970964764/
1 、死锁的概念
是指两个或两个以上的事务在执行过程中,因争夺资源而造成的一种互相等待的现象。若无外力作用,事务都将无法推进下去,解决死锁的最简单问题是不要有等待,任何的等待都转换为回滚,并且事务重新开始,但在线上环境,这可能会导致并发性能下降,甚至任何一个事务都不能进行,而这所带来的问题远比死锁的问题更严重
解决死锁的问题最简单的一种方法是超时,当两个事务互相等待时,当一个等待时间超过设置的某一阈值时,其中一个事务回滚,另一个等待的事务就能继续运行了,在InnoDB存储引擎中,参数innodb_lock_wait_timeout用来设置超时时间
超时机制虽然简单,但是其仅通过超时后对事务进行回滚的方式处理,或者说其是根据FIFO的顺序选择回滚对象,但若超时的事务所占权重比较大,如事务操作更新了很多航,占用了较多的undo log,这是采用FIFO方式,就显得不合适了,因为回滚这个事务的时间相对另一个事务所占用的时间可能会更多
除了超时机制,当前的数据库还采用wait-for graph(等待图)的方式来进行死锁检测,较之超时的解决方案,这是一种更为主动的死锁检测方式。InnoDB存储引擎也是采用这种方式。wait-for graph要求数据库保存以下两种信息
锁的信息链表
事务等待链表
通过上述链表可以构造出一张图。而这个在图中若存在回路,就代表存在死锁,因此资源间相互发生等待,在wait-for graph,事务为图中的节点,而在图中,事务T1指向T2边的定义为
事务T1等待事务T2所占用的资源
事务T1最终等待T2所占用的资源,也就是事务之间在等待相同的资源,而事务T1发生在事务T2的后面
看一个例子,当前事务和锁的状态如图
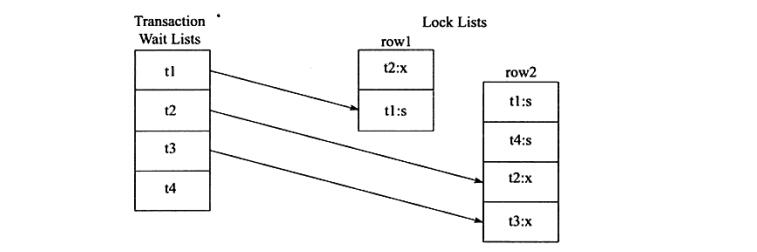
在Transaction Wait Lists中可以看到共有4个事务t1、t2、t3、t4,故在wati-for graph中应有4个节点。而事务t2对row1占用X锁,事务t1对row2占用s锁.事务t1需要等待t2中row1的资源,因此在wait-for graph中有条从节点t1指向节点t2.事务t2需要等待事务t1、t4锁占勇row2对象,故此存在节点t2到节点 t1 t4的边,同样,存在节点t3到节点t1 t2 t4的边,因此最终wait-for graph为
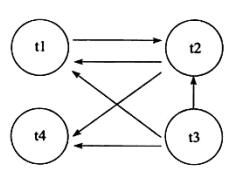
如图,可以发现回路(t1,t2)因此存在死锁。通过上述介绍,可以发现wait-for graph是一种较为主动的死锁检测机制,在每个事务请求锁并发生等待时都会判断是否存在回路,若存在则有死锁,通常来说,InnoDB存储引擎会选择回滚undo量最小的事务
wait-for graph的死锁检测通常采用深度优先的算法实现,在InnoDB1.2版本之前,都是采用递归方式实现,而1.2版本开始,对wait-for graph死锁检测进行了优化,将递归用非递归的方式实现,从而提高了InnoDB存储引擎的性能
2、 死锁概率
死锁应该非常少发生,若经常发生,则系统是不可用的。此外,死锁的次数应该还要少于等待,因为至少需要2次等待才会产生一次死锁,从数学角度来分析,死锁发生的概率问题
当前数据库中有n+1个线程执行,即当前总共有n+1事务,假设每个事务所做的操作相同,若每个事务由r+1个操作组成,每个操作从R行数据中随机操作一行数据,并占用对象的锁,每个事务在执行完最后一个步骤释放锁占用的所有锁资源,最后,假设nr<<R即线程操作的数据只占所有数据的一小部分
在上述模型下,事务获得一个锁需要等待的概率是多少?当事务获得一个锁,其他任何一个事务获得锁的情况为
(1+2+3...+r)/(r+1) ≈r/2
由于每个操作为从R行数据中取一条数据,每行数据被取到的概率为1/R,因此,事务中每个操作需要等待的概率PW为
PW=NR/2R
事务由r个操作锁组成,因此事务发生等待的概率PW(T)为
PW(T)=1-(1-PW)r≈r*PW≈nr2/2R
死锁是由于产生贿赂,也就是事务互相等待发生的,如果死锁的长度为2,即两个等待的节点间发生死锁,那么其概率为
一个事务发生死锁的概率≈PW(T) 2/n≈nr4/4R2
由于大部分死锁的长度为2,因此上述的公式基本代表了一个事务发生死锁的概率。从整个系统来看,任何一个事务发生死锁的概率为
系统中任何一个事务发生死锁的概率≈n2r4/4R2
上述公式可以发现,由于nr<<R,因此,发生死锁的概率是非常低的,同时,事务发生死锁的概率与以下几点因素有关:
事务中事务的数量n,数量越多发生死锁的概率越大
每个事务操作的数量r,每个事务操作的数量越大,发生死锁的概率越大
操作数据的集合R,越小发生死锁的概率越大
3、 死锁示例
如果程序是串行的,不可能发生死锁,死锁只存在于并发的情况,而数据库本身就是一个并发运行的程序,因此可能发生斯说,下面延时了死锁的一种经典情况,即A等待B,B等待A,这种死锁被称为AB-BA死锁

在上述操作中,会话B中的事务会抛出1213的错误,即表示发生死锁,死锁的原因是会话A和会话B的资源在互相等待。大多数死锁InnoDB存储引擎本身可以侦测到,不需要人为干预,但是在上述例子中,在会话B中的事务抛出死锁异常后,会话A中马上得到了记录为2的这个资源,这其实是因为会话B中的事务发生了回滚,否则会话A中的事务是不可能得到该资源的,InnoDB存储引擎是不会回滚大部分的错误异常,但是死锁除外。发生死锁后,InnoDB存储引擎会马上回滚一个事务,这点需要注意,因此如果在应用程序中捕获1213这个错误,其实并不需要对其进行回滚
Oracle数据库中产生死锁的常见原因是没有对外键添加索引,而InnoDB存储引擎会自动对其进行添加,因而能够很好的避免这种情况发生,而人为删除外键上的索引,就会抛出异常
>create table p(
a int,
primary key(a)
)engine=innodb;
>create table c(
b int,
foreign key(b)references p(a)
)engine=innodb;
>show index from c;
此时我们删除
>drop index b on c
Error Code: 1553. Cannot drop index 'b': needed in a foreign key constraint
可以看到,虽然在建立子表时指定了外键,但是InnoDB存储引擎会自动在外键列上建立一个索引b,并且人为的删除这个列是不允许的
此外还存在另一种死锁,即当前事务持有了待插入记录的下一个记录的X锁,但是在等待队列中存在一个S锁的请求,则可能发生死锁,来看一个列子
DROP TABLE t;
CREATE TABLE t(
a INT PRIMARY KEY
)ENGINE=INNODB;
INSERT INTO t VALUES(1),(2),(4),(5);
表t仅有一列a并插入了4条记录,运行如下查询
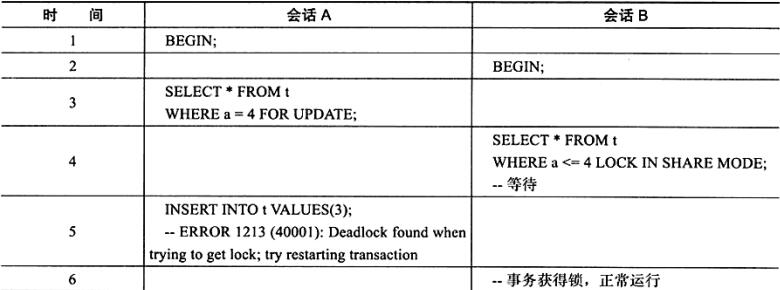
可以看到,会话A已经对记录4持有X锁,但是在会话A中插入记录3时会导致死锁发生,这个问题的产生是由于会话B中请求记录4的S锁而发生等待,但之前请求的锁 对于主键记录1 2都已经成功,若在事件点5能插入记录,那么会话B在获得记录4持有的S锁后,还需要向后获得记录3的记录,这样显然不合理。因此InnoDB存储引擎在这里主动选择死锁,而回滚的是undo log记录大的事务,这与AB-BA的死锁处理方式又不同