1.什么是Lucene?
作为一个开放源代码项目,Lucene从问世之后,引发了开放源代码社群的巨大反响,程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建Web应用,甚至某些商业软件也采用了Lucene作为其内部全文检索子系统的核心。apache软件基金会的网站使用了Lucene作为全文检索的引擎,IBM的开源软件eclipse的2.1版本中也采用了Lucene作为帮助子系统的全文索引引擎,相应的IBM的商业软件Web Sphere中也采用了Lucene。Lucene以其开放源代码的特性、优异的索引结构、良好的系统架构获得了越来越多的应用。
Lucene作为一个全文检索引擎,其具有如下突出的优点:
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search)、分组查询等等。
2.什么是solr?
为什么要solr:
solr是将整个索引操作功能封装好了的搜索引擎系统(企业级搜索引擎产品)
solr可以部署到单独的服务器上(WEB服务),它可以提供服务,我们的业务系统就只要发送请求,接收响应即可,降低了业务系统的负载
solr部署在专门的服务器上,它的索引库就不会受业务系统服务器存储空间的限制
solr支持分布式集群,索引服务的容量和能力可以线性扩展
solr的工作机制:
solr就是在lucene工具包的基础之上进行了封装,而且是以web服务的形式对外提供索引功能
业务系统需要使用到索引的功能(建索引,查索引)时,只要发出http请求,并将返回数据进行解析即可
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
3.lucene和solr的关系
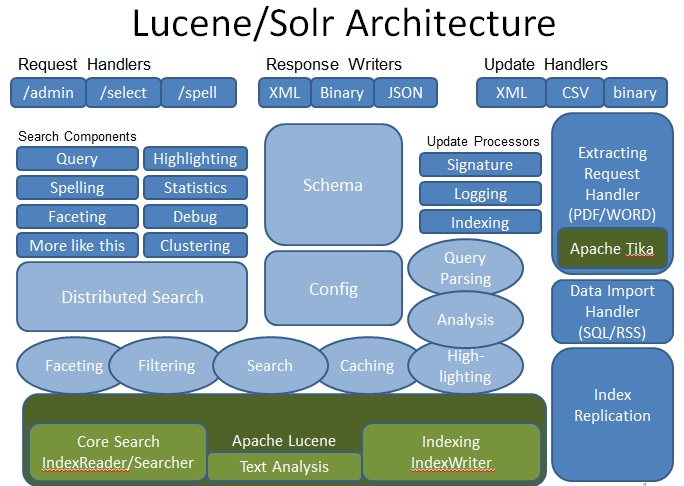
solr是门户,lucene是底层基础,solr和lucene的关系正如hadoop和hdfs的关系。
4.Jetty是什么?
Jetty 是一个开源的servlet容器,它为基于Java的web容器,例如JSP和servlet提供运行环境。Jetty是使用Java语言编写的,它的API以一组JAR包的形式发布。开发人员可以将Jetty容器实例化成一个对象,可以迅速为一些独立运行(stand-alone)的Java应用提供网络和web连接。
5.流程概况
6.Jetty接收请求并处理
设置本地调试见<lucene-solr本地调试方法>所示
StartSolrJetty.java
public static void main( String[] args )
{
//System.setProperty("solr.solr.home", "../../../example/solr");
Server server = new Server();
ServerConnector connector = new ServerConnector(server, new HttpConnectionFactory());
// Set some timeout options to make debugging easier.
connector.setIdleTimeout(1000 * 60 * 60);
connector.setSoLingerTime(-1);
connector.setPort(8983);
server.setConnectors(new Connector[] { connector });
WebAppContext bb = new WebAppContext();
bb.setServer(server);
bb.setContextPath("/solr");
bb.setWar("solr/webapp/web");
// // START JMX SERVER
// if( true ) {
// MBeanServer mBeanServer = ManagementFactory.getPlatformMBeanServer();
// MBeanContainer mBeanContainer = new MBeanContainer(mBeanServer);
// server.getContainer().addEventListener(mBeanContainer);
// mBeanContainer.start();
// }
server.setHandler(bb);
try {
System.out.println(">>> STARTING EMBEDDED JETTY SERVER, PRESS ANY KEY TO STOP");
server.start();
while (System.in.available() == 0) {
Thread.sleep(5000);
}
server.stop();
server.join();
}
catch (Exception e) {
e.printStackTrace();
System.exit(100);
}
}
其中,Server是http服务器,聚合了Connector(http请求接收器)和请求处理器Hanlder,Server本身是一个handler和一个线程池,Connector使用线程池来调用handle方法。
/** Jetty HTTP Servlet Server.
* This class is the main class for the Jetty HTTP Servlet server.
* It aggregates Connectors (HTTP request receivers) and request Handlers.
* The server is itself a handler and a ThreadPool. Connectors use the ThreadPool methods
* to run jobs that will eventually call the handle method.
*/
其工作流程如下图所示
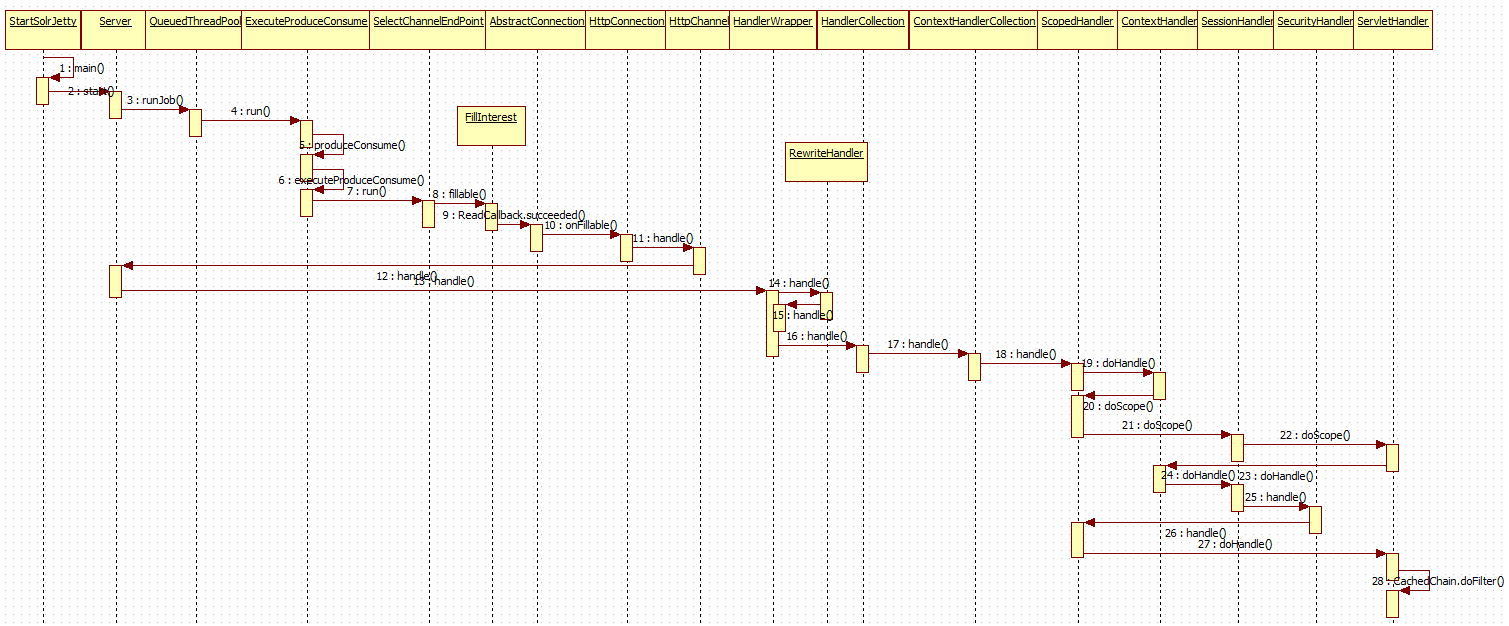
因其不是本文重点,故略去不述。
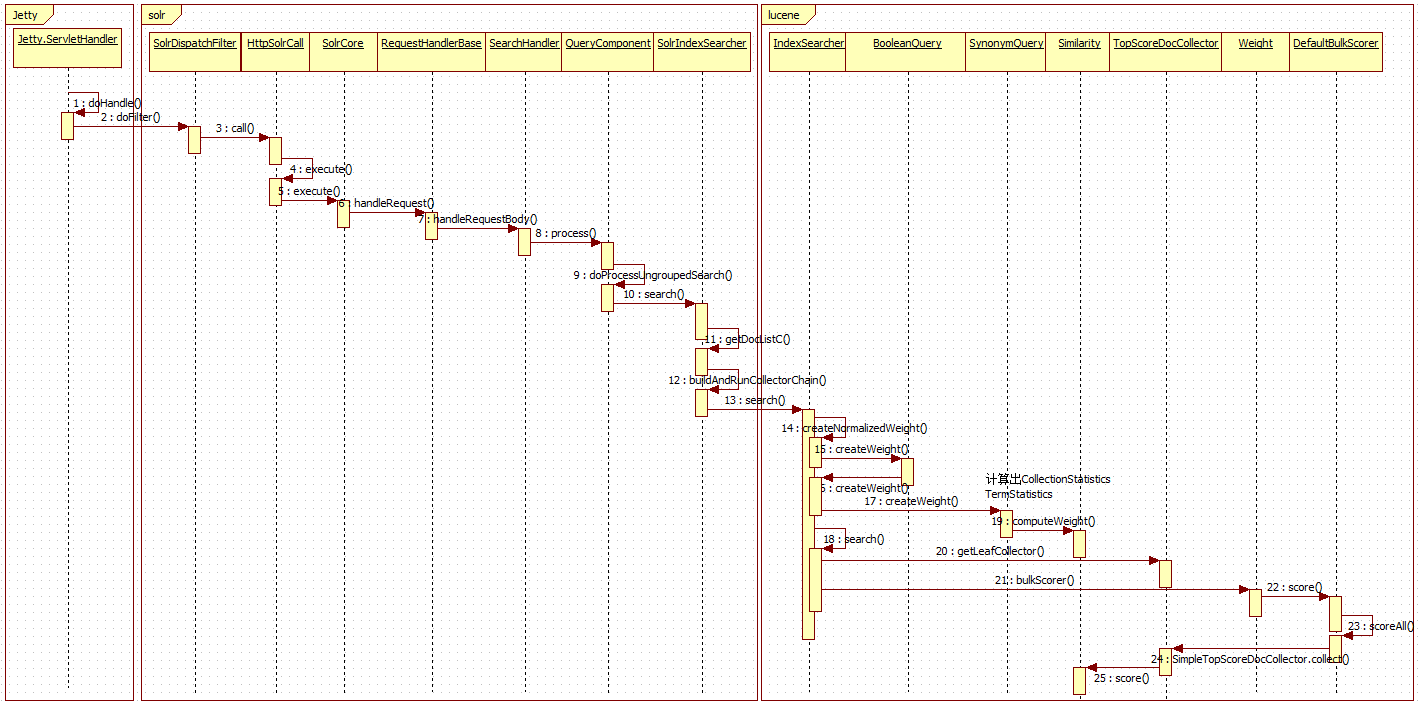
7.solr调用lucene过程
上篇文章<solr调用lucene底层实现倒排索引源码解析>已经论述,可对照上面的整体流程图进行解读,故略去不述
8.lucene调用过程

从上图可以看出分两个阶段
8.1 创建Weight
8.1.1 创建BooleanWeight
BooleanWeight.java
BooleanWeight(BooleanQuery query, IndexSearcher searcher, boolean needsScores, float boost) throws IOException {
super(query);
this.query = query;
this.needsScores = needsScores;
this.similarity = searcher.getSimilarity(needsScores);
weights = new ArrayList<>();
for (BooleanClause c : query) {
Query q=c.getQuery();
Weight w = searcher.createWeight(q, needsScores && c.isScoring(), boost);
weights.add(w);
}
}
8.1.2 同义词权重分析
SynonymQuery.java
@Override
public Weight createWeight(IndexSearcher searcher, boolean needsScores, float boost) throws IOException {
if (needsScores) {
return new SynonymWeight(this, searcher, boost);
} else {
// if scores are not needed, let BooleanWeight deal with optimizing that case.
BooleanQuery.Builder bq = new BooleanQuery.Builder();
for (Term term : terms) {
bq.add(new TermQuery(term), BooleanClause.Occur.SHOULD);
}
return searcher.rewrite(bq.build()).createWeight(searcher, needsScores, boost);
}
}
8.1.3 TermQuery.java
@Override
public Weight createWeight(IndexSearcher searcher, boolean needsScores, float boost) throws IOException {
final IndexReaderContext context = searcher.getTopReaderContext();
final TermContext termState;
if (perReaderTermState == null
|| perReaderTermState.wasBuiltFor(context) == false) {
if (needsScores) {
// make TermQuery single-pass if we don't have a PRTS or if the context
// differs!
termState = TermContext.build(context, term);
} else {
// do not compute the term state, this will help save seeks in the terms
// dict on segments that have a cache entry for this query
termState = null;
}
} else {
// PRTS was pre-build for this IS
termState = this.perReaderTermState;
}
return new TermWeight(searcher, needsScores, boost, termState);
}
调用TermWeight,计算CollectionStatistics和TermStatistics
public TermWeight(IndexSearcher searcher, boolean needsScores,
float boost, TermContext termStates) throws IOException {
super(TermQuery.this);
if (needsScores && termStates == null) {
throw new IllegalStateException("termStates are required when scores are needed");
}
this.needsScores = needsScores;
this.termStates = termStates;
this.similarity = searcher.getSimilarity(needsScores);
final CollectionStatistics collectionStats;
final TermStatistics termStats;
if (needsScores) {
termStates.setQuery(this.getQuery().getKeyword());
collectionStats = searcher.collectionStatistics(term.field());
termStats = searcher.termStatistics(term, termStates);
} else {
// we do not need the actual stats, use fake stats with docFreq=maxDoc and ttf=-1
final int maxDoc = searcher.getIndexReader().maxDoc();
collectionStats = new CollectionStatistics(term.field(), maxDoc, -1, -1, -1);
termStats = new TermStatistics(term.bytes(), maxDoc, -1,term.bytes());
}
this.stats = similarity.computeWeight(boost, collectionStats, termStats);
}
调用Similarity的computeWeight
BM25Similarity.java
@Override
public final SimWeight computeWeight(float boost, CollectionStatistics collectionStats, TermStatistics... termStats) {
Explanation idf = termStats.length == 1 ? idfExplain(collectionStats, termStats[0]) : idfExplain(collectionStats, termStats);
float avgdl = avgFieldLength(collectionStats);
float[] oldCache = new float[256];
float[] cache = new float[256];
for (int i = 0; i < cache.length; i++) {
oldCache[i] = k1 * ((1 - b) + b * OLD_LENGTH_TABLE[i] / avgdl);
cache[i] = k1 * ((1 - b) + b * LENGTH_TABLE[i] / avgdl);
}
return new BM25Stats(collectionStats.field(), boost, idf, avgdl, oldCache, cache);
}
8.2 查询过程
完整过程如下:IndexSearcher调用search方法
protected void search(List<LeafReaderContext> leaves, Weight weight, Collector collector)
throws IOException {
// TODO: should we make this
// threaded...? the Collector could be sync'd?
// always use single thread:
for (LeafReaderContext ctx : leaves) { // search each subreader
final LeafCollector leafCollector;
try {
leafCollector = collector.getLeafCollector(ctx);//1
} catch (CollectionTerminatedException e) {
// there is no doc of interest in this reader context
// continue with the following leaf
continue;
}
BulkScorer scorer = weight.bulkScorer(ctx);//2
if (scorer != null) {
try {
scorer.score(leafCollector, ctx.reader().getLiveDocs());//3
} catch (CollectionTerminatedException e) {
// collection was terminated prematurely
// continue with the following leaf
}
}
}
}
8.2.1 获取Collector
TopScoreDocCollector.java#SimpleTopScoreDocCollector
@Override
public LeafCollector getLeafCollector(LeafReaderContext context)
throws IOException {
final int docBase = context.docBase;
return new ScorerLeafCollector() {
@Override
public void collect(int doc) throws IOException {
float score = scorer.score();
/* Document document=context.reader().document(doc);
*/
// This collector cannot handle these scores:
assert score != Float.NEGATIVE_INFINITY;
assert !Float.isNaN(score);
totalHits++;
if (score <= pqTop.score) {
// Since docs are returned in-order (i.e., increasing doc Id), a document
// with equal score to pqTop.score cannot compete since HitQueue favors
// documents with lower doc Ids. Therefore reject those docs too.
return;
}
pqTop.doc = doc + docBase;
pqTop.score = score;
pqTop = pq.updateTop();
}
};
}
8.2.2 调用打分socore
/**
* Optional method, to return a {@link BulkScorer} to
* score the query and send hits to a {@link Collector}.
* Only queries that have a different top-level approach
* need to override this; the default implementation
* pulls a normal {@link Scorer} and iterates and
* collects the resulting hits which are not marked as deleted.
*
* @param context
* the {@link org.apache.lucene.index.LeafReaderContext} for which to return the {@link Scorer}.
*
* @return a {@link BulkScorer} which scores documents and
* passes them to a collector.
* @throws IOException if there is a low-level I/O error
*/
public BulkScorer bulkScorer(LeafReaderContext context) throws IOException {
Scorer scorer = scorer(context);
if (scorer == null) {
// No docs match
return null;
}
// This impl always scores docs in order, so we can
// ignore scoreDocsInOrder:
return new DefaultBulkScorer(scorer);
}
/** Just wraps a Scorer and performs top scoring using it.
* @lucene.internal */
protected static class DefaultBulkScorer extends BulkScorer {
private final Scorer scorer;
private final DocIdSetIterator iterator;
private final TwoPhaseIterator twoPhase;
/** Sole constructor. */
public DefaultBulkScorer(Scorer scorer) {
if (scorer == null) {
throw new NullPointerException();
}
this.scorer = scorer;
this.iterator = scorer.iterator();
this.twoPhase = scorer.twoPhaseIterator();
}
@Override
public long cost() {
return iterator.cost();
}
@Override
public int score(LeafCollector collector, Bits acceptDocs, int min, int max) throws IOException {
collector.setScorer(scorer);
if (scorer.docID() == -1 && min == 0 && max == DocIdSetIterator.NO_MORE_DOCS) {
scoreAll(collector, iterator, twoPhase, acceptDocs);
return DocIdSetIterator.NO_MORE_DOCS;
} else {
int doc = scorer.docID();
if (doc < min) {
if (twoPhase == null) {
doc = iterator.advance(min);
} else {
doc = twoPhase.approximation().advance(min);
}
}
return scoreRange(collector, iterator, twoPhase, acceptDocs, doc, max);
}
}
调用scoreAll方法,遍历Document,执行SimpleTopScoreDocCollector的collect方法,包含打分逻辑<见SimpleTopScoreDocCollector代码>。
/** Specialized method to bulk-score all hits; we
* separate this from {@link #scoreRange} to help out
* hotspot.
* See <a href="https://issues.apache.org/jira/browse/LUCENE-5487">LUCENE-5487</a> */
static void scoreAll(LeafCollector collector, DocIdSetIterator iterator, TwoPhaseIterator twoPhase, Bits acceptDocs) throws IOException {
if (twoPhase == null) {
for (int doc = iterator.nextDoc(); doc != DocIdSetIterator.NO_MORE_DOCS; doc = iterator.nextDoc()) {
if (acceptDocs == null || acceptDocs.get(doc)) {
collector.collect(doc);
}
}
} else {
// The scorer has an approximation, so run the approximation first, then check acceptDocs, then confirm
final DocIdSetIterator approximation = twoPhase.approximation();
for (int doc = approximation.nextDoc(); doc != DocIdSetIterator.NO_MORE_DOCS; doc = approximation.nextDoc()) {
if ((acceptDocs == null || acceptDocs.get(doc)) && twoPhase.matches()) {
collector.collect(doc);
}
}
}
}
总结:
梳理整理整个流程太累了。
参考资料
【1】http://www.blogjava.net/hoojo/archive/2012/09/06/387140.html